As anyone in the imaging market knows, the medical imaging market is not dominated by any vendor even if it quite a bit less fragmented than the EHR market. Look at these reports on PACS and modalities (e.g., X-Ray, CT, MRI, Ultrasound, et cetera). It's fairly common for an organization to have one vendor's PACS solution, another's modality, and a diagnostic workstation from a third.
The reason that these different systems work together inside an institution is because they adhere to the DICOM standards. But there is a little bit more to it. It is also because someone has taken the time ensure that they are configured appropriately to work together. Once you get outside the walls of the organization though, you need more attention to interoperability. The number of systems you want to be able to work with is even broader.
Let's look at a common use case (the one that John Halamka wrote about earlier today): Getting an imaging study done, and having it be used at a different organization or facility. The most common mechanism for exchange of the study is to create a CD. Every time a family member of mine has had a significant imaging study done, we ask for the data on a CD before we leave, and we know to do so as early on as we can to simplify our lives. Every CD I have ever received has included a viewer on it. Only one included both Mac and Windows viewers. Others just included a Windows viewer. Those viewers are not meant for diagnostic quality viewing. They are really just simple programs that allow a provider without any other viewing technology to see what is on the CD. Any provider that I've ever really needed to give a CD to has had better viewing technology than what was on the CD.
Importing a CD from a foreign institution is not 100% successful, because not everyone complies with the standards. David Clunie (considered by many to be the father of DICOM) talks about this in a paper he presented at RSNA in 2010. Most of the CD import failures are attributable to NOT following the DICOM standard, or other relevant specifications. The Great Aussie CD Challenge (pdf) tested more than two dozen CDs in 2007 for standards conformance (an eternity in Internet years), and came to similar conclusions with regard to conformance. I'd love to see a more recent repeat of this exercise, using newer technology because the situation has improved (PDI was first introduced as an IHE profile in 2005).
This study showed that nearly 80% of CDs can be imported successfully. There are standards and profiles which could improve the success rate (and which were used in the CD challenge previously mentioned). The IHE Portable Data for Imaging Profile was strongly recommended by this Johns Hopkins study, in Australia (as a result of the challenge), and by the AMA.
This report shows the number of organizations that support PDI in their products. It is an amazing list, which includes all of the vendors previously named in the market share reports at the top of this post.
What it doesn't show and is even more important is how many provider organizations are actually using those capabilities. As Dr. Clunie's paper indicates, it is very likely that organizations aren't configuring their systems to USE the AVAILABLE standards and profiles. One question that they need to address is what the value is for them to do so. As John Moehrke points on in this post from last year, getting your "Damn Data" seems to require a mandate to do so interoperably. This isn't an implementation issue with respect to standards, but rather a deployment one. I've implemented PDI in 2008, and actually done so over top of the XDS-I specifications. It was one of the simplest standards-based integrations I've ever done. Getting someone to want to use it? That's a different story.
Exchanging data on CD isn't ideal. There are a number of issues beyond dealing with the data in a standard format that also have to be addressed, many of which Dave Clunie points out in his RSNA slides. Others are addressed in this 2008 Radiographics article by Mendolson and others. These include things like patient identification, translation of procedure codes used at different organizations, bandwidth and storage issues, et cetera.
Ideally, you'd think it would just be a matter of transmission of the study from the organization where the study was done to the organization where it is going to be reviewed. Pragmatically, that doesn't work where we live because the value of that "network" isn't perceived by anyone other than the patient, unless the imaging center and the reviewer are somehow financially connected. Payers do see the value, and where I live, the possibility that a payer network would be established to support such an imaging exchange is certainly viable, but has yet to be realized.
Point-to-point exchange (e.g, via Direct) wouldn't really have worked in one case for one of my family members, because we didn't know who the specialist who was going to perform the surgery was until long after the image was taken (but reading the CD was really simple). You need something like the network in Philadelphia and New Jersey, or in Canada described in the Radiographics article above. These networks are built upon the IHE XDS for Imaging protocols. Both IHE and NEMA are also working on the next generation of web-service enabled protocols to support more advance image sharing.
John Halamka proposes the use of The Direct protocol to exchange images. The Direct project was designed to support clinical data which is several orders of magnitude smaller than imaging study data. This article documents the size of some typical imaging studies (see Table 3). These range from 15Mb to as much as 1Gb (for CT Angiography). Moving forward into the world of advanced digital imaging for pathology, you could get into the terabyte range (that's more than a 1000 CDs, a hundred DVD's or a double handful of Blue-Ray disks). Clinical data, such as that in a CCD takes from a few Kb to maybe a couple of Mb if someone has abused the standard to provide a full data dump.
Anyone who's had any experience sending multi-megabyte files over e-mail will probably realize the limited viability of Direct for anything other than simple studies (e.g., X-Ray or Ultrasound). The reality is that providers using the "simplest of EHR systems" probably won't have the storage capacity available to deal with medium-to-large studies.
One of the rationals for the way DICOM is structured is that you don't need all the data all of the time. Studies are large, but what the provider often needs to view is much smaller. The tie-in to transport in the DICOM standard was to address this issue, and transport only what is needed when it is needed for viewing. That's a much more efficient use of network bandwidth, and still gives providers what they need, which is, according to the AMA, access to the complete diagnostic quality study data.
With regard to proprietary data, and viewers: There is no need to physically separate proprietary data in the image stream, but there is a need to tag it so that a "vendor-neutral viewer" can process the data, and DICOM does that. Every proprietary data item in a DICOM conforming object is clearly tagged as such, and if you read the Vendor's DICOM conformance statements, those tags are documented. And if they conform to IHE's PDI profile, they will also have a DICOM conformance statement. If the system conforms to the DICOM standard, you don't need to understand the proprietary data to view the image. There are really good reasons why some systems use proprietary data, and store it within the DICOM study. But that data should not impact a standards-conforming viewer.
We don't need a new standard to address most of what John complains about in his blog post. What we need is for organizations to actually USE the standards which are already widely available, and to configure their systems to do so. That would address a large part of the existing problem. Canada has certainly shown with their deployment that XDS-I works for regional imaging exchange. Regarding the companies that John mentioned on his blog, all three support XDS-I in their solutions.
The one case where a new standard is needed is in the interchange across distributed networks of DICOM study data. That is work that DICOM has already started. I should note that the DICOM standard applies to regulated medical devices. I will happily leave the development of the new DICOM standards to experts in diagnostic imaging. I don't think throwing a lot of non-expert volunteers at the problem will make that work go any faster, or produce better outcomes.
Keith
Tuesday, January 31, 2012
The Professional and the Patient
Being a patient is, unlike most other experiences in this world, a life skill, rather than a professional skill. You don't get paid for it (in fact, it has significant personal costs, not just financial). Even people who get paid to represent patients are applying other professional skills (speaking, communications, lobbying, even painting and singing), and are using those skills with existing experiences as either a patient or patient advocate.
This makes for interesting challenges for Healthcare conference organizers. After all, they are designed to cater to a professional audience who can afford to travel and pay conference fees. This is a business concern that conference organizers must address. A recent blog post talks about how one patient representative will NO SHOW on conferences that has:
There are engaged and committed patients and advocates who are willing to participate in conferences around healthcare. But these people (and I include myself in that lot), are not representative of the typical patient. And many patients and advocates don't have a source of funding that allow them to participate as a patient representative.
This all makes for a very difficult dynamic in the overall conversation about healthcare. That dynamic is further complicated by the lack of transparency in healthcare regarding costs.
As an engaged patient, I won't stop attending conferences that have no patients in the program, on the stage, or in the audience. But I will approach the issue with conference leaders to show what the value is of taking that approach. Patients can provide needed input and value to these conferences, and if we can communicate that to conference leaders, we can change how they approach patient engagement. After all, as an engaged patient, my role is to try to figure out how to get professionals to engage back. To break off the communication, especially at this stage, doesn't seem to be a useful tactic.
Keith
This makes for interesting challenges for Healthcare conference organizers. After all, they are designed to cater to a professional audience who can afford to travel and pay conference fees. This is a business concern that conference organizers must address. A recent blog post talks about how one patient representative will NO SHOW on conferences that has:
- no patient IN the program,
- no patient ON the stage or
- no patient IN the audience.
There are engaged and committed patients and advocates who are willing to participate in conferences around healthcare. But these people (and I include myself in that lot), are not representative of the typical patient. And many patients and advocates don't have a source of funding that allow them to participate as a patient representative.
This all makes for a very difficult dynamic in the overall conversation about healthcare. That dynamic is further complicated by the lack of transparency in healthcare regarding costs.
As an engaged patient, I won't stop attending conferences that have no patients in the program, on the stage, or in the audience. But I will approach the issue with conference leaders to show what the value is of taking that approach. Patients can provide needed input and value to these conferences, and if we can communicate that to conference leaders, we can change how they approach patient engagement. After all, as an engaged patient, my role is to try to figure out how to get professionals to engage back. To break off the communication, especially at this stage, doesn't seem to be a useful tactic.
Keith

Monday, January 30, 2012
IHE Pharmacy Technical Framework Supplements Published for Trial Implementation
|
||
|

Friday, January 27, 2012
IHE IT Infrastructure White Paper on HIE Published
This white paper shows you how the IHE profiles work together to provide a standards-based, interoperable approach to health information exchange. If you are involved in an HIE, and want to understand the standards and technology that can be used to support information exchange, this is a good document to read. At 35 pages, it is a short document, but it packs a great deal of information that HIE CTO's and architects should know.
The white paper addresses four key technical challenges:
- Sharing models, including push, pull (Query/Retrieve), and Federation
- Patient Identity Management
- Patient and Sharing Partner Discovery
- Security and Privacy
Because it is focused on the technical infrastructure, the white paper does not address the content profiles that have been developed by a number of IHE domains which can be used with the technical infrastructure. That will likely be the topic of a future white paper from Patient Care Coordination.
-- Keith

IHE Community,
IHE IT Infrastructure White Paper Published
The IHE IT Infrastructure Technical Committee published the following white paper on January 24, 2012:
· Health Information Exchange: Enabling Document Sharing Using IHE Profiles
The document is available for download at http://bit.ly/IHEDocSharing. Comments can be submitted at http://www.ihe.net/iti/iticomments.cfm.
IHE IT Infrastructure White Paper Published
The IHE IT Infrastructure Technical Committee published the following white paper on January 24, 2012:
· Health Information Exchange: Enabling Document Sharing Using IHE Profiles
The document is available for download at http://bit.ly/IHEDocSharing. Comments can be submitted at http://www.ihe.net/iti/iticomments.cfm.
Thursday, January 26, 2012
In Honor of Kay Hammond
I usually never give away the recipient of the Ad Hoc Harley award, because that is part of the fun of it. But this one is different. Kay Hammond died yesterday. Kay is the wife of Ed Hammond, and a long time supporter of Ed's work at HL7. What I remember of Kay is her ballroom dancing with Ed at an HL7 reception, and her exceptionally strong support of him through the years. She was an exceptional dancer (as is Ed), and she loved to travel, often joining Ed at HL7 International working group meetings.
What Kay did in her life should help us all remember is that among all the volunteers who make the Health IT Standards happen, there are a number of people who didn't volunteer, but without whom, some of this work would never happen. They get to deal with long absences of their spouses several times a year (weeks at a stretch at times), sometimes going to sleep alone even when their spouse is home because they are up until impossible hours wrangling with some crazy deadline. But they keep the home fires burning, caring for children and managing their own careers at the same time while we are working on the standards. They willingly share their garage with stacks upon stacks of paper or computer parts, deal with missed birthdays, anniversaries and holidays with great poise, all for relatively little reward -- perhaps the occasional exotic (or more often, not so exotic) trip with their spouse who is only free some part of the time.
Please keep Ed and his family in your thoughts today as they mourn the passing of Kay. Remember also those in your own families who support you in your work in standards, as Kay always supported Ed.

Thank you Kay. The award is virtual, but so now are you. God speed.
Please join me also if you wish in making a memorial contribution in memory of Mrs. Kay Hammond to Duke Cancer Institute supporting cancer research, checks may be written to the Duke Cancer Fund, and mailed to Duke Cancer Institute DUMC, Box 3828 Durham, NC 27710.
What Kay did in her life should help us all remember is that among all the volunteers who make the Health IT Standards happen, there are a number of people who didn't volunteer, but without whom, some of this work would never happen. They get to deal with long absences of their spouses several times a year (weeks at a stretch at times), sometimes going to sleep alone even when their spouse is home because they are up until impossible hours wrangling with some crazy deadline. But they keep the home fires burning, caring for children and managing their own careers at the same time while we are working on the standards. They willingly share their garage with stacks upon stacks of paper or computer parts, deal with missed birthdays, anniversaries and holidays with great poise, all for relatively little reward -- perhaps the occasional exotic (or more often, not so exotic) trip with their spouse who is only free some part of the time.
Please keep Ed and his family in your thoughts today as they mourn the passing of Kay. Remember also those in your own families who support you in your work in standards, as Kay always supported Ed.
This Ad Hoc Harley is awarded posthumously to
Kay Stuart Forrester Hammond
for her demonstration of support for
Healthcare Standardization

Thank you Kay. The award is virtual, but so now are you. God speed.
Please join me also if you wish in making a memorial contribution in memory of Mrs. Kay Hammond to Duke Cancer Institute supporting cancer research, checks may be written to the Duke Cancer Fund, and mailed to Duke Cancer Institute DUMC, Box 3828 Durham, NC 27710.
The XSLT document() function
Yesterday, someone asked a question about how to address issues of translating a code to a display name on one of the the Structured Documents workgroup's e-mail lists. There's a technique that I've been using in XSLT for quite some time that allows me to access look-up tables very easily without having to embed translation logic in the XSLT stylesheet. Before I describe the technique, I thought I'd share some of the various uses for it:
<xsl:variable name="myDocument" select="document('mydocument.xml')"/>
This creates a variable which can be used in an XPath expression subsequently in your XML. In the use case the querant posed, the issue was how to get a display name for a language code, to that the patients preferred language (expressed as a code) could be displayed in the UI. The patient's language preferences are stored in the patient/languageCommunication/languageCode/@code attribute.
The following XSLT fragment shows a template that will return the display name of the patient language by looking it up through an XML document.
<xsl:variable name="langs" select="document('lang.xml')"/>
...
<xsl:template name='patientLanguage'>
<!-- get the code -->
<xsl:variable name='lang'
select='//patient/languageCommunication/languageCode/@code'/>
<xsl:variable name='mappedLang' select='$langs//language[@code=$lang]'/>
<xsl:choose>
<xsl:when test='$mappedLang'>
<xsl:value-of select='$mappedLang/@displayName'/>
</xsl:when>
<xsl:otherwise>Unknown</xsl:otherwise>
</xsl:choose>
</xsl:template>
The same technique can also be used to access a resource that is created dynamically through a RESTful web-server end-point. I demonstrate one use of this technique in the post on Values Sets and Query Health.
Another use for this technique is to check value-set conformance inside Schematron rules. If you have a requirement that code/@code come from a particular value set, you can write a rule that accesses a web resource based on the value set, as in the following example:
<rule context='*/cda:templateId[@root = templateIdentifier]'>
...
<let name='code' value='cda:code/@code'/>
<let name='valueSetDoc' value='document("https://example.com/RetrieveValueSet?id=1.2.840.10008.6.1.308")'/>
<assert test='$valueSetDoc//ihe:Concept[@code = $code]'>
The code/@code element must come from the XXX Value Set (OID: 1.2.840.10008.6.1.308)
</assert>
</rule>
The use of external XML data files is a very powerful feature of XSLT. Combining that use with dynamically created XML resources through web services makes it even more capable.
- Code translation. Often you will have codes in a one code system that need to be translated into codes from another code system. This technique allows you to look up the translation. I've used this to translate local codes to codes from standard vocabularies for:
- Unit translation from ANSI+ to UCUM
- Local codes for problem severity to SNOMED codes for severity used in the HITSP C32
- Local codes for problem status to SNOMED codes for problem status.
- Local codes for problem type to SNOMED codes for problem type.
- Local codes for vital signs to LOINC codes for vital signs.
- Display name lookup. Closely related to #1 above. Often times, I have a standard code, but not the display name associated with it. I can use this technique on small value sets (less that 1000 codes) to look up the display name (this is the use case for the problem presented on the list).
- Mapping from an identifier to a web service end point. You can use this technique to map from:
- The home community ID to an XCA Web Service address
- A DICOM AE Title to a WADO Web Service endpoint.
- Validating against a dynamically changing rule, such as the validation of a code element against the current version of a vocabulary or value set.
<xsl:variable name="myDocument" select="document('mydocument.xml')"/>
This creates a variable which can be used in an XPath expression subsequently in your XML. In the use case the querant posed, the issue was how to get a display name for a language code, to that the patients preferred language (expressed as a code) could be displayed in the UI. The patient's language preferences are stored in the patient/languageCommunication/languageCode/@code attribute.
The following XSLT fragment shows a template that will return the display name of the patient language by looking it up through an XML document.
<xsl:variable name="langs" select="document('lang.xml')"/>
...
<xsl:template name='patientLanguage'>
<!-- get the code -->
<xsl:variable name='lang'
select='//patient/languageCommunication/languageCode/@code'/>
<xsl:variable name='mappedLang' select='$langs//language[@code=$lang]'/>
<xsl:choose>
<xsl:when test='$mappedLang'>
<xsl:value-of select='$mappedLang/@displayName'/>
</xsl:when>
<xsl:otherwise>Unknown</xsl:otherwise>
</xsl:choose>
</xsl:template>
The same technique can also be used to access a resource that is created dynamically through a RESTful web-server end-point. I demonstrate one use of this technique in the post on Values Sets and Query Health.
Another use for this technique is to check value-set conformance inside Schematron rules. If you have a requirement that code/@code come from a particular value set, you can write a rule that accesses a web resource based on the value set, as in the following example:
<rule context='*/cda:templateId[@root = templateIdentifier]'>
...
<let name='code' value='cda:code/@code'/>
<let name='valueSetDoc' value='document("https://example.com/RetrieveValueSet?id=1.2.840.10008.6.1.308")'/>
<assert test='$valueSetDoc//ihe:Concept[@code = $code]'>
The code/@code element must come from the XXX Value Set (OID: 1.2.840.10008.6.1.308)
</assert>
</rule>
The use of external XML data files is a very powerful feature of XSLT. Combining that use with dynamically created XML resources through web services makes it even more capable.
Wednesday, January 25, 2012
A Hex upon all your charsets
Today's post results from a question someone posed to me about how to render XDS-SD content using an XSLT stylesheet. If you've tried to do this for application/pdf content, you've probably already discovered that there is no way* to use an XSLT stylesheet to render your content on either the server or the client side.
The critical issue for this morning's querant was how to render text/plain content, and that can be done (see this post), provided that you have a way to access a procedural language from your XSLT stylesheet (which almost all production level XSLT transformers do). The solution is platform specific but is generally applicable. In fact, if you are using Xalan, the solution works across most Java implementations and Xalan versions. A C#/.Net solution is certainly possible along the same lines as the one I suggest.
But there is a challenge here, and that is determining the base character set of the text/plain content. When that content is purely ASCII, it is likely to work on any system, because almost all character sets use the same first 128 characters as ASCII does (the main exceptions are EBCDIC, which you may never encounter, and UTF-16 or its older sibling UCS-2). The problem only occurs when someone base-64 encodes text that contains extended characters (like any of these Å æ ç é í ñ ö ß û). At that point, character set becomes critical for correct rendering.
Let's take Å for example. In ANSI/ISO-8859-1/Windows Code Page 1252, this character is Hex C5, and is encoded in a single byte. In UTF-8, this character would be encoded in two bytes, the first being Hex C3, and the second being Hex A5. In UTF-16 or UCS-2, this character would be encoded in two bytes, the first being Hex 00, and the second being Hex C5, or Hex C5 followed by Hex 00.
These bytes will render in interesting ways on systems that aren't handling them right. For example, the UTF-8 character represented by the sequence C3, A5 will show up as å in a system expecting ANSI/ISO-8859-1.
So, this matters for display purposes, and you need to know what character set the text/plain data was represented in. So how do you figure this out? The first thing to do is look at the IHE XDS-SD profile, but it doesn't say (because that's a property of the HL7 CDA standard that IHE didn't profile in XDS-SD). nonXMLBody/text is of the ED data type in HL7. When we look there, we see that data type has the charset property, so all we need to do it get that, and we're all set, right? Wrong.
Unfortunately, while the data type covers it, the XML Implementation of the ED data type does not. It says:
My hope was this would be corrected in Data Types R2 ITS and/or Data Types R1.1, but apparently its been totally missed.
My advice for now: If you are a content producer of XDS-SD documents using text/plain content is to use only ASCII characters in your content if you can. I'll bet more than 95% of the documents using that format do that today in any case. The long term solution will be for IHE to apply a CP to XDS-SD that says that for text/plain, the content must be stored in the _____ encoding, where the blank will be filled in after a good bit of discussion. I would expect that UTF-8 would be a strong contender. And in HL7 we need to fix the ITS, because charset on ED needs to be present when it is base-64 encoded.
If you are a content consumer, when you decode the text, look for any non-ASCII characters in it. If there are some present, you are going to have to guess at the encoding. If not, you can just stick with ASCII.
In the meantime, all I have to say is ?@*#$%~!
-- Keith
* Actually there is a way described here, and it uses the data: URL described in RFC 2397, but this is not supported across all platforms and media types (IE for example, does not support the data: URL for all objects, only images).
The critical issue for this morning's querant was how to render text/plain content, and that can be done (see this post), provided that you have a way to access a procedural language from your XSLT stylesheet (which almost all production level XSLT transformers do). The solution is platform specific but is generally applicable. In fact, if you are using Xalan, the solution works across most Java implementations and Xalan versions. A C#/.Net solution is certainly possible along the same lines as the one I suggest.
But there is a challenge here, and that is determining the base character set of the text/plain content. When that content is purely ASCII, it is likely to work on any system, because almost all character sets use the same first 128 characters as ASCII does (the main exceptions are EBCDIC, which you may never encounter, and UTF-16 or its older sibling UCS-2). The problem only occurs when someone base-64 encodes text that contains extended characters (like any of these Å æ ç é í ñ ö ß û). At that point, character set becomes critical for correct rendering.
Let's take Å for example. In ANSI/ISO-8859-1/Windows Code Page 1252, this character is Hex C5, and is encoded in a single byte. In UTF-8, this character would be encoded in two bytes, the first being Hex C3, and the second being Hex A5. In UTF-16 or UCS-2, this character would be encoded in two bytes, the first being Hex 00, and the second being Hex C5, or Hex C5 followed by Hex 00.
These bytes will render in interesting ways on systems that aren't handling them right. For example, the UTF-8 character represented by the sequence C3, A5 will show up as å in a system expecting ANSI/ISO-8859-1.
So, this matters for display purposes, and you need to know what character set the text/plain data was represented in. So how do you figure this out? The first thing to do is look at the IHE XDS-SD profile, but it doesn't say (because that's a property of the HL7 CDA standard that IHE didn't profile in XDS-SD). nonXMLBody/text is of the ED data type in HL7. When we look there, we see that data type has the charset property, so all we need to do it get that, and we're all set, right? Wrong.
Unfortunately, while the data type covers it, the XML Implementation of the ED data type does not. It says:
charset is not explicitly represented in the XML ITS. Rather, the value of charset is to be inferred from the encoding used in the XML entity in which the ED value is contained.The problem with this statement is that it is entirely true when the ED data type is not base-64 encoded, it is false when it is so encoded. At that point, the encoding is of text/plain content that is entirely independent of the character encoding of the XML document. In fact, the character encoding of the XML document can change independently and without any disruption of the XML content (because XML is Unicode, no matter how the document is transmitted). But the base-64 encoded text/plain content will not change its encoding because the characters are now those of the base-64 encoding. The encoding of the base64 characters can change, but that won't change how the content they are encoding will decode. Confused? Yeah, me too.
My hope was this would be corrected in Data Types R2 ITS and/or Data Types R1.1, but apparently its been totally missed.
My advice for now: If you are a content producer of XDS-SD documents using text/plain content is to use only ASCII characters in your content if you can. I'll bet more than 95% of the documents using that format do that today in any case. The long term solution will be for IHE to apply a CP to XDS-SD that says that for text/plain, the content must be stored in the _____ encoding, where the blank will be filled in after a good bit of discussion. I would expect that UTF-8 would be a strong contender. And in HL7 we need to fix the ITS, because charset on ED needs to be present when it is base-64 encoded.
If you are a content consumer, when you decode the text, look for any non-ASCII characters in it. If there are some present, you are going to have to guess at the encoding. If not, you can just stick with ASCII.
In the meantime, all I have to say is ?@*#$%~!
-- Keith
* Actually there is a way described here, and it uses the data: URL described in RFC 2397, but this is not supported across all platforms and media types (IE for example, does not support the data: URL for all objects, only images).
Tuesday, January 24, 2012
Balance is of the Essence
Time is of the essence.In a contract this means that failure to complete the work by the agreed up deadline constitutes a breach. Deadlines enable cost controls and ensure predictability. In yesterday's post I talked briefly about Federal Engagement in Standards development. One of the key phrases used in communication at the Federal level about their standards strategy is "Impatient Convener". There are a number of other activities where speed seems to be essential.
A counterpoint to this focus on "speed" is doing it right.
There is never enough time to do it right, but there's always enough time to do it over. -- Jack Bergman
Make Haste Slowly - Anonymous
Only that which is well done is quickly done. -- AugustusHow do you balance the imperatives of time and quality? In the three-legged triangle of project management, you must be able to balance resources, quality and functionality. When any two are fixed, the other must be variable.
According to the triangle inequality (|A| + |B| > |C|), there are collections of triangle sides that don't work.
We (standards professionals) have to be careful with how we address issues where time is of the essence. A failure to meet the deadline is certainly a problem, but even worse would be a failure to deliver on quality or worse yet, to deliver something that doesn't add the necessary value.
What is truly essential to success is balance.
Monday, January 23, 2012
On Principles for Federal Engagement in Standards Activities to Address National Priorities
The following showed up in my inbox this morning.
In general, I think this is great policy advice, especially the section on Agency Responsibilities starting at the bottom of page 3.
What I'd liked to emphasize is this statement found on the middle of page 2:
I hope we won't have another situation like the one where HITSP wound up orphaning documents that were the result of more than 100,000 hours of community expertise. We really do need to figure out how to get to level 5 in this country.
In general, I think this is great policy advice, especially the section on Agency Responsibilities starting at the bottom of page 3.
What I'd liked to emphasize is this statement found on the middle of page 2:
To accomplish these objectives, the Federal Government, as directed by Congress, is taking a convening role to accelerate standards development, by working closely with domestic and international private sector standards organizations.I work closely with SDOs, and I know what it means to do so. I cannot give the Federal Government high marks here, although I have to admit that they've gotten better over the last year. If they mean to sustain the good work going on in the S&I Framework activities, they'll have to do better. The S&I contracts will end, and that means someone will have to maintain the outputs.
I hope we won't have another situation like the one where HITSP wound up orphaning documents that were the result of more than 100,000 hours of community expertise. We really do need to figure out how to get to level 5 in this country.
Friday, January 20, 2012
New MeaningfulUse Rule will likely impact Stage 1 Criteria
Most Health IT folks today are concerned about Meaningful
Use for Stage 2, but they should also be concerned about stage 1 as well. Under new Federal Regulation for meaningful
use, it is certainly possible that the definition of stage 1 meaningful use can
change. As the Meaningful Use Standards final
rule stated:
The stages of criteria of meaningful use and how they are demonstrated are described further in this final rule and will be updated in subsequent rulemaking to reflect advances in HIT products and infrastructure. We note that such future rulemaking might also include updates to the Stage 1 criteria.
The real question for many is what that will mean for
vendors implementing products, and providers attesting to meaningful use at a
particular stage. For vendors, it is very clear that EHR products will need to be
certified against the new criteria as soon as possible, because again,
according to both the final rule for temporary certification and for permanent certification:
Regardless of the year and meaningful use stage at which an eligible professional or eligible hospital enters the Medicare or Medicaid EHR Incentive Program, the Certified EHR Technology that they would need to use would have to include the capabilities necessary to meet the most current certification criteria adopted by the Secretary at 45 CFR 170 subpart C.
When Stage 2 becomes effective (anticipated for 2014),
providers will need to upgrade to EHR technology that is certified to
that criteria, regardless of whether they are attesting to Stage 1 or Stage 2
of Meaningful Use criteria. The new incentives rule will contain criteria defined for those organizations who
are a “Stage 1” Meaningful User and for those who are a “Stage 2” Meaningful
User. Stage 2 users will have more criteria to attest to, and for those capabilities already existing in stage 1, a higher degree of use of those capabilities (e.g., A higher percentage of orders performed electronically at stage 2 than stage 1). Regardless of whether they are at Stage 1 or Stage 2, both kinds of organizations
will have to use EHR technology that has been certified to support the Stage 2
criteria.
The table below shows the current Stage 1 standards and the stage
2 standards that I’m currently projecting for the new Meaningful Use Standards rule.
|
|
Stage 1
|
Stage 2
|
||
|
|
January 2011 – December 2013
|
January 2014 – ?
|
||
|
Purpose
|
Standard
|
Implementation Guide
|
Standard
|
Implementation Guide
|
|
Generating a Clinical Summary
|
CCD 1.0
|
HITSP C32 V2.5
|
CDA R2.0
|
CCD 1.1
(Stage 1) |
|
CCR
|
|
|
CDA Consolidation Guide (Stage
2)
|
|
|
Viewing a Clinical Summary
|
Both
CCR and HITSP C32 V2.5
|
CDA
Consolidation Guide, CCR and HITSP C32 V2.5
|
||
|
Immunizations
|
HL7 V2.3.1
|
CDC 2.3.1 Guide
|
|
|
|
HL7 V2.5.1
|
CDC 2.5.1 Guide
|
HL7 2.5.1
|
CDC 2.5.1 Guide
|
|
|
Public Health Lab Reporting
|
HL7 V2.5.1
|
ELR Guide
|
|
ELR Guide and/or updated LRI Guide
|
|
Disease Surveillance
|
HL7 V2.3.1
|
No Guide Selected
|
|
|
|
HL7 V2.5.1
|
HL7 V2.5.1
|
PHIN Guide
|
||
The new certification criteria for Stage 1 and Stage 2 will almost assuredly require use of new standards, and some standards previously acceptable will be dropped. The biggest challenge for many will be the change from
CCR/HITSP C32 V2.5 to CDA® and the CDA Consolidation Guide, and that is what
this post will focus upon. The key question is how systems conforming to the new standards will address the issue
of the legacy data stored using either CCR or the HITSP C32 2.5.
Fortunately, ONC cleverly created two separate criteria
for the clinical summary. The first was
generating (and subsequently transmitting) an electronic summary. ONC allowed two formats for that capability: CCR or
the HITSP C32 2.5, of which a provider need choose only one (but could support
both). However, all systems must support
viewing both (and need not do any more than that).
In order to support
viewing of legacy documents, I fully expect that the new certification criteria
will require certified systems to support viewing of legacy content. I also expect it to support viewing of any document
found in the CDA Consolidation guide. With
the exception of the Unstructured Document, viewing is not a challenge. IHE implementers have learned over the years to
sign up for the “Content Consumer” actor for all PCC Profiles of the HL7 CDA if they
can support content consumer for ANY document because you get it nearly for free. Most implementations transform CDA to HTML or XHTML and display the results. A good
stylesheet handles all content equally well.
Thus, it is reasonable to ask these systems to support viewing of any
CDA based content under the new certification criteria. If you can view one kind of CDA document using
an XSL stylesheet, you should be able to view many. There are numerous sources of code for CDA
stylesheets freely available.
The Unstructured Document in the CDA Consolidation guide needs
more work for viewing but there are plenty of viewing technologies available to
support its requirements as well. There's another whole post that I will devote to that topic.
On the creation side, I expect that systems must be able to
create content using the CDA Consolidation Guide. A stage 1 meaningful user might only be
required to generated CCD 1.1 documents, but a Stage 2 user might be required
to support not just CCD 1.1 but could be permitted or even required to generate
other document types in the CDA Consolidation Guide (e.g., discharge summary).
Where backwards compatibility becomes a problem for organizations
that are exceeding the meaningful use requirements, such as the Beacon
programs. Those organizations have been
working with CCD 1.0 and will now need to support CCD 1.1. That is one of the penalties of getting out
in front. The key for those programs
will be adapting their technology that uses the HITSP C32 V2.5 to use CCD
1.1. It may be a PITA, but this is
really not a hard challenge.
Given the origins of CCD 1.1, it should certainly be feasible
to transform from CCD 1.0 to CCD 1.1 automatically. While there are some incompatibilities between the two versions, a valid HITSP C32 Version 2.5 will almost certainly
transform into a valid CCD 1.1 for the purpose of importing, reconciliation, et
cetera. The transition to CCD 1.1 even
prior to its adoption as a certification requirement could be done within the
context of the single system that makes use of it, enabling innovators to take
advantage of it before it becomes a requirement.
Shortly HL7 will be releasing the latest CDA Consolidation
template database, and the Model Driven Health Tools project will be releasing
a version which includes the CDA Consolidation rules. Those two model driven tools will provide
engineers (including me) with a lot more information than we’ve ever had
previously to make the transition to the new format easier.
-- Keith
Thursday, January 19, 2012
Microdata Shot Down but still flying for CDA
Graham Grieve shot down my HTML5 + Microdata proposal Tuesday with a well-placed comment on the ease of writing micro-data [or actually the lack there-of]. I’m borrowing from Calvin Beebe’s suggestion (he’s an HL7 Structured Document Workgroup Chair) that there be a way to transform back and forth between formats to support some of the capabilities provided by HTML5 + Microdata, and still maintain the ease of writing (and validating) CDA documents in XML.
While, I’m still convinced that we need to use HTML5 for the text portion of the document, and still really like what Microdata does for you with the document in the browser. But now I acknowledge that we will probably need to allow HTML5 and some RIM (or perhaps FHIR [pronounced Fire]) based XML representation of content. Whether it be RIM-based or FHIR-based, call it HL7 XML and lets move on.
In order to resolve Graham’s issue though, I’ll need a way to translate back and forth between HTML5 + HL7 XML and HTML5 + Microdata. The only thing I can count on being in common between FHIR and another HL7 XML format is that they are XML, so I’m just going to work on Microdata to XML and back transformation.
Here is some of my initial thinking on the transformation:
While, I’m still convinced that we need to use HTML5 for the text portion of the document, and still really like what Microdata does for you with the document in the browser. But now I acknowledge that we will probably need to allow HTML5 and some RIM (or perhaps FHIR [pronounced Fire]) based XML representation of content. Whether it be RIM-based or FHIR-based, call it HL7 XML and lets move on.
In order to resolve Graham’s issue though, I’ll need a way to translate back and forth between HTML5 + HL7 XML and HTML5 + Microdata. The only thing I can count on being in common between FHIR and another HL7 XML format is that they are XML, so I’m just going to work on Microdata to XML and back transformation.
Here is some of my initial thinking on the transformation:
- The transformation may be guided by an XML schema, but this is not a requirement.
- Transformation to Microdata and back should be possible.
- The itemprop attribute represents the name of the element or attribute. When the value of itemprop begins with an @ character, it will be represented as an attribute in the XML. When it begins with any other character it will be represented as an element. Since @ isn’t a legal name start in XML, this seems like it should work.
- The itemtype attribute must represent the Schema type of the element or attribute in the form URL#typename, where URL is the namespace URL associated with element or attribute in the schema, and the typename is the name of the complex or simple type in the schema.
- When there is no namespace URL associated with the Schema, the URL shall be TBD.
- Properties which are represented in the XML as attributes are given names of the form: @name where name is the attribute name.
- An attribute can be assigned more than one property value if its schema simple type is defined using
- .
- Properties which are represented in the XML as elements are given names of the form: name where name is the element name.
- What is cool about this transformation is that I also get (for free), a JSON and RDF interpretation along with the Microdata representation of the machine readable metadata.
-
Associating an XML Document with an HTML 5 element as microdata without an Schema is pretty easy. You traverse the DOM of the XML Document an:
- Start with the HTML 5 element to which the XML document is to be associated as Microdata.
- Add itemscope to the HTML 5 element.
- Add itemprop to the HTML 5 element using the name of the element.
- If there is an xsi:type attribute associated with the element, set the itemtype to be the namespace URL for the type, followed by # followed by the type name.
- For each attribute of the element, add a new item to the item associated with the HTML 5 element. That item will have an itemprop value of @ plus the attribute name. Set itemValue to be the value of the attribute.
- For each child element, add a new item to the item associated with the HTML 5 element. Recurse at step 1 above.
Wednesday, January 18, 2012
NwHIN open to Non-Federal Partners
This showed up in my inbox today... it is a long overdue and welcome change. As I read it, it means that organizations that aren't contracting with the government can take advantage of the NwHIN in the US.
A key goal of the HITECH Act is to enable the secure exchange of health information to improve health and care. ONC, its Federal partners, and other stakeholders have been working through many programs to achieve this goal, including work on the nationwide health information network (NwHIN), the NwHIN Exchange, and the Direct Project. Until now, participation in the Exchange has been limited to Federal agencies and outside organizations that have contracts, grants, or cooperative agreements with them. However, with the evolution of both the NwHIN and the
Exchange, ONC has determined that this limitation is no longer needed. Participants who currently participate under contracts, grants, or cooperative agreements can continue in that capacity, and when those formal relationships expire, their signature on the Data Use and Reciprocal Support Agreement (DURSA) is sufficient (along with other specified requirements). New entities wishing to join need only sign the DURSA and fulfill other requirements. This is effective immediately, and the number of new participants is expected to grow steadily over the course of 2012. This is an important step in supporting wider health
information exchange for Meaningful Use and broader national goals for better health and health care.
Mary Jo Deering, Ph.D.
Senior Policy Advisor
Office of the National Coordinator for Health Information
Technology
U.S. Department of Health and Human Services
300 C Street, S.W., #1103
Washington, DC 20201
Tuesday, January 17, 2012
A National Standards Maturity Model
Rene Spronk had a great post on the HL7 Affiliate Life Cycle a few weeks back. Yesterday Catherine Chronaki displayed a simple slide based on that model at the HL7 Working Group meeting. While Rene talks about it from an HL7 Perspective, I think about it from a national perspective. There are essentially five levels in Rene's model:
So far, only Canada is at level 5. The US through Meaningful Use is sort of at level 4 for endorsement of HL7 standards, and the ONC S&I Framework is certainly a level 2 activity, if not officially acting as an HL7 Affiliate.
The S&I Framework contracts (there are at least 10) will eventually end. There are a lot of activities which have produced outputs that still need maintenance (e.g., the Clinical Element Data Dictionary). One of the tasks for the S&I Framework is to establish a long term, public-private mechanism to sustain these activities, which could push the US to level 5.
When I think about all the national standards activities impacting the US:
- Raising Awareness
- Creating Consensus Based Localization
- Paid Development
- Official Endorsement
- Standards Collaborative
So far, only Canada is at level 5. The US through Meaningful Use is sort of at level 4 for endorsement of HL7 standards, and the ONC S&I Framework is certainly a level 2 activity, if not officially acting as an HL7 Affiliate.
The S&I Framework contracts (there are at least 10) will eventually end. There are a lot of activities which have produced outputs that still need maintenance (e.g., the Clinical Element Data Dictionary). One of the tasks for the S&I Framework is to establish a long term, public-private mechanism to sustain these activities, which could push the US to level 5.
When I think about all the national standards activities impacting the US:
- S&I Framework (US Localization)
- IHE USA (US Deployment and Testing)
- SCO (National Coordination)
- US TAG to ISO TC215 (International Coordination)
- HIMSS Interoperability Workgroup
- NCPDP (eRX)
- X12N (Insurance and Payment)
- NeHC (Education)
And several of the International ones:
It becomes pretty clear that we need a US Standards Collaborative. Here are some of my thoughts on it from two years ago.
Sunday, January 15, 2012
Blacking out for SOPA Script
Tonight I thought I would write a little script to black out this site on January 18th in protest against proposed US SOPA legislation. After about 5 minutes of research, I found the work that someone else had done and freely shared on the Internet. This is all it takes:
<script type="text/javascript" src="http://js.sopablackout.org/sopablackout.js"></script>
If you are running Blogger (as this site is), you can simply insert this code inside an HTML Widget that appears on your blog page on January 18th, and take it down later.
Feel free to pirate this page for your own use.
<script type="text/javascript" src="http://js.sopablackout.org/sopablackout.js"></script>
If you are running Blogger (as this site is), you can simply insert this code inside an HTML Widget that appears on your blog page on January 18th, and take it down later.
Feel free to pirate this page for your own use.
Friday, January 13, 2012
Give it to ME
I've been reading quite a bit about all of the consumer oriented mobile health apps that have shown up lately. There's been a lot of buzz around this especially given the recent Consumer Electronics Show that just concluded (thankfully). There's also been quite a bit of discussion about a recent mobile health app that works with Health Vault.
All these apps are simply creating new mobile silos of information, or worse yet, requiring us to go through some third party cloud storage in order to manage and view it. I want my damn data and I want you to give it to ME so that I can analyze it. It's my health. Let me do with the data what I want easily, without having to hack my tablet, or use your website. At the very least, give me the ability to export the data to a spreadsheet.
Patients (and consumers) want to use a variety of different applications. We want to be able to collect that data and do stuff with it. Right now, I've got two separate apps, one to track my weight, and the other to track my blood pressure. In order to see the impact of one on the other, I've got to go through quite a bit of gyration just to put it together in one place.
All these apps are simply creating new mobile silos of information, or worse yet, requiring us to go through some third party cloud storage in order to manage and view it. I want my damn data and I want you to give it to ME so that I can analyze it. It's my health. Let me do with the data what I want easily, without having to hack my tablet, or use your website. At the very least, give me the ability to export the data to a spreadsheet.
Patients (and consumers) want to use a variety of different applications. We want to be able to collect that data and do stuff with it. Right now, I've got two separate apps, one to track my weight, and the other to track my blood pressure. In order to see the impact of one on the other, I've got to go through quite a bit of gyration just to put it together in one place.
Thursday, January 12, 2012
Blue Button
Chris W. brings up Blue Button on the Ask me a Question page, and a few weeks ago it popped up again into my radar screen. In case you've been in hiding for the past year, Blue Button is the name of a VA initiative to enable vets to download their clinical information in an ASCII text format from the VA patient portal MyHealtheVet. It's based on a Markle Foundation specification which has gotten quite a bit of attention.
Recently the Office of Personnel Management sent a letter to health plans participating in the Federal Employee Health Benefit Program (FEHBP). I found an interesting quote in the letter (I underlined the interesting part):
Chris's main point is this (and I quote):
The scope of the project is to:
From my perspective, Blue Button is beneficial to patients, but not as big a step forward as it could be. (my S4PM friends may want to disown me for saying so, but hey, that's the way I feel). I'd much rather spend my energy on CDA Release 3 and HTML 5.
Given the importance of this project, I will be paying attention to it, and Chris is so right. Because of all the work that has already been done in CCD, this will be pretty easy. I just wish I could get some focused time on what will really move things forward.
Recently the Office of Personnel Management sent a letter to health plans participating in the Federal Employee Health Benefit Program (FEHBP). I found an interesting quote in the letter (I underlined the interesting part):
Supplying your members with the simple, low-cost and readily available Blue Button function will strengthen your contractual HIT obligations under FEHBP, align with the Meaningful Use standards laid out by Health and Human Services (HHS), and most importantly, empower your members to know their health information and make informed choices based on that information.According to the letter, you would assume that you could download the records in the electronic standard formats suggested by HHS under Meaningful Use. But wait, the Blue Button specification is just ASCII text. It doesn't follow that standard at all, and many provider and payer organizations have already implemented according the HITSP C32 Version 2.5 (one of the two allowed standards under Meaningful Use Stage 1). Sometimes I wish the left hand and the right hand would communicate a little bit better.
Chris's main point is this (and I quote):
... it occurs to me that the effort is promising (for the intended use cases) precisely because of the standardization that HL7 has been driving behind the scenes. That is, the tag sets and value formats (and vocabularies) will have a fairly high level of consistency across organizations right out of the box because of their prior work on adopting a variety of standards internally, and especially HL7 standardsIn fact, there's an HL7 project which is working its way through channels to create an XSL Stylesheet that will translate the semantically interoperable, Meaningful Use conforming HITSP C32 into the Blue Button format. Structured Documents approved it today, and it goes next to the steering division and then the TSC for final approval.
The scope of the project is to:
... produce a sample XSLT schema and background text on usage that will transform a CDA R2 CCD file into a U.S. Department of Veteran Affairs (VA) Blue Button ASCII text file.It's likely going to have to make some sacrifices to fit within the specifications required for Blue Button, because there's more that you can say and do in CDA and CCD that Blue Button accounts for.
From my perspective, Blue Button is beneficial to patients, but not as big a step forward as it could be. (my S4PM friends may want to disown me for saying so, but hey, that's the way I feel). I'd much rather spend my energy on CDA Release 3 and HTML 5.
Given the importance of this project, I will be paying attention to it, and Chris is so right. Because of all the work that has already been done in CCD, this will be pretty easy. I just wish I could get some focused time on what will really move things forward.
Tuesday, January 10, 2012
Logistic Growth of EHR users under MeaningfulUse
 |
| Logistic Growth Curve (courtesy of Wikipedia) |
Recently, HHS released data on Meaningful Use attestations (through November of last year) on Data.gov. Brian Ahier posted a couple of extractions from this data earlier today. The data includes the following elements:
| Variable Name | Definition |
| Vendor Name | Name of EHR vendor |
| EHR Product Name | Name of EHR product |
| EHR Product Version | Version of EHR product |
| Product Classification | Whether product meets all Meaningful Use requirements (Complete) or meets only part of the Meaningful Use requirements (Modular) |
| Product Setting | Practice setting for which product is designed for (Ambulatory or Inpatient) |
| Attestation month | Month that the provider successfully attested to MU |
| Business State/Territory | Business location of provider who successfully attested to MU (state/territory) |
| Provider Type | Whether attestor was an eligible professional (EP) or eligible hospital (Hospital) |
| Specialty | Specialty or provider type |
| Program Year | Year of EHR Incentive Program |
| Payment Year | Payment year of EHR Incentive Program |
| Program Type | Whether the attestor registered under Medicare or Medicare/Medicaid |
| ID | Unique ID for each Attestor |
I put together a quick pivot chart report which showed the number of attestations by month for Meaningful Use, and looked at the growth trend. Here is how it looked:

| Month | Attestations |
| 4 | 506 |
| 5 | 812 |
| 6 | 1045 |
| 7 | 1461 |
| 8 | 2268 |
| 9 | 3774 |
| 10 | 5754 |
| 11 | 7341 |
What this chart clearly shows is that we are still in the exponential growth stage for attestations. I found some information on logistic curve fitting data. It required an estimation of the saturation point for the population, so I looked up the number of physician practices from Wikipedia and applied it to the model. Given the the disparity between EP attestations (21,461) and Hospital attestations (1,500), I figured that an estimate of 250,000 was sufficient.
What I wanted to find out by this was when MU would be "done" (i.e., CMS would be "saturated" with attestations), and my results were rather surprising. So I went back and checked it again with two other estimates (125K and 500K). Then I took the 95% confidence interval on my low and high estimates. I plotted it out so that you could see the range of possible answers here:
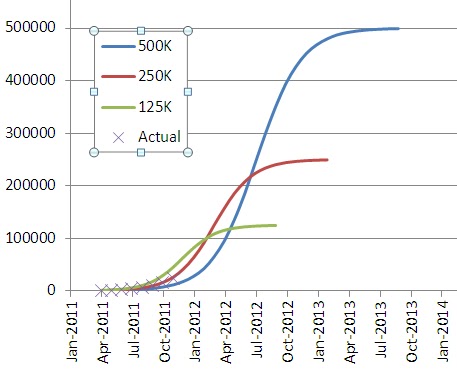
What this shows me is that by mid-year of 2012, we'll be halfway to saturation, and by the end of 2013, we'll have reached saturation. And if I'm too high on my estimate of providers, it will be by October of 2012, and if I'm to low it will be by October of 2013.
Now, my 95% bands were on the transformed linear equation, so I don't know how that impacts things with respect to confidence bands (I could figure it out, but I'm not that deeply interested). What this tells me is that Meaningful Use, rather than being "off schedule" appears to be ahead of schedule. I still don't know if I believe that.
One thing this model doesn't account for is how many providers attesting were already EHR users, and so were ready to attest, vs. those that have yet to adopt. I suspect that the market is just a bit more complex than a simple logistic curve can account for, but even if it is, there's still another whole year before "Meaningful Use" is over using the figures I went with. I'd stick with the "ahead of schedule" estimate at this point.
So, 2012 should see EHR adoption rates at several multiples of the current rate. We'll look at the numbers again when they've released new data to see how things are going.
Subscribe to:
Comments (Atom)