I've been working on trying to clean up HL7's temporal vocabulary for HQMF. The problem is with boundary conditions as it is relevant to time relationships. We have two boundaries, the start and end of an event, and three comparison operations (less than, equal to and greater than), which gets me to twelve different vocabulary terms, which gives me all the atoms needed, right?
Wrong. We are dealing with intervals, and intervals can be open or closed. While < and = together make up <=, we cannot use two vocabulary terms to specify a SINGLE relationship. So in order to describe the <= relationship between two items, we actually need to have five different comparators, <, <=, =, >= and >. This is still NOT a closed set of relationships over the inverse operator, because we are missing <> (or != if you prefer that notation).
So we now have two choices from the source of the relationship, either the start or the end, six comparison operators, and two choices for the target of the relationship (again, start or end) = 2 x 6 x 2 = 24 different terms.
One of my desires is to avoid complexity for implementers. Twenty-four vocabulary terms seems to be too complex. Do we really need to support >=, <= and != ? After all, these are just the same as NOT <, NOT > and NOT =, and we could achieve NOT with the negationInd attribute in the RIM. But using negationInd doesn't make it any simpler, and in fact, divides the problem up across two different attributes (negationInd and typeCode). We already have existing vocabulary supporting >= and <=, because we have terms for OVERLAP which needs to deal with these operation.
So, I decided to look at it a different way. In a time range, there are five discrete parts. Before the start, the start, after the start and before the end, the end, and after the end. We need to be able to talk about any of these five parts in sequence. If we label the parts A, B, C, D and E, we need to be able to talk about:
I'm going to reorganize the remaining acts, and show how they relate to temporal comparisons in the following diagram:
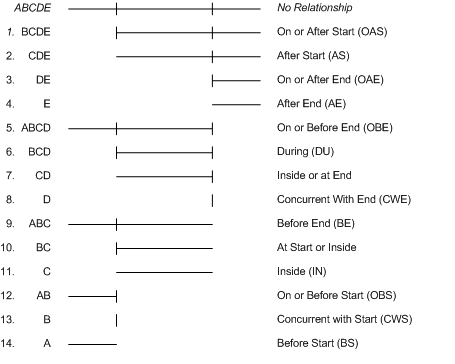
Each of these defines a time range related to a target act. We can indicate that the start of the source act occurs within each of these ranges, or the end of the source act occurs within them to define some useful relationships. The names of these relationships would be something like SAS or EAS to represent Start after Start, or End after Start. That's nice because those are already HL7 vocabulary terms. So, now we can apply S and E to each of the above, and get 28 relationships. Hmm, this is a dead end isn't it. After all, didn't we want something smaller than 24?
It gets worse. If you've been swift, you might also note that there are some tests where you want to test both start and end of the source act. The existing OVERLAP, DURING and CONCURRENT are examples of temporal relationships that do this. So now we are up to 31 or more. Yech.
I'm sorry to report, it doesn't get better (at least yet). After some more digging, I found a paper (which I should have looked for first). James F. Allen published a paper in 1983 that reports that there are 213 = 8192 possible relationships that can be described between two definite intervals. Dr. Thomas Alspaugh provides a great explanation of Allen's paper. You should probably read that summary to understand the rest of this post.
Dr. Alspaugh explains that there are 13 basic relationships between two intervals. These 13 basic relationships are distinct (meaning each can be distinguished from the other), exhaustive (because the relationship between any two intervals A and B can always be identified as following one of these patterns), and is purely qualitative.
Where things get interesting in Allen's algebra is when Alspaugh produces a table that shows what happens when you "compose" a relationship. Composition of a relationship describes the how to compute the relationship r.s that between A and C, when A r B and B s C. As it turns out, there are 27 "composite" relations when you perform composition over the original set of 13 basic relationships.
So, I looked over the 27 different relationships, and this is what I found:
Wrong. We are dealing with intervals, and intervals can be open or closed. While < and = together make up <=, we cannot use two vocabulary terms to specify a SINGLE relationship. So in order to describe the <= relationship between two items, we actually need to have five different comparators, <, <=, =, >= and >. This is still NOT a closed set of relationships over the inverse operator, because we are missing <> (or != if you prefer that notation).
So we now have two choices from the source of the relationship, either the start or the end, six comparison operators, and two choices for the target of the relationship (again, start or end) = 2 x 6 x 2 = 24 different terms.
One of my desires is to avoid complexity for implementers. Twenty-four vocabulary terms seems to be too complex. Do we really need to support >=, <= and != ? After all, these are just the same as NOT <, NOT > and NOT =, and we could achieve NOT with the negationInd attribute in the RIM. But using negationInd doesn't make it any simpler, and in fact, divides the problem up across two different attributes (negationInd and typeCode). We already have existing vocabulary supporting >= and <=, because we have terms for OVERLAP which needs to deal with these operation.
So, I decided to look at it a different way. In a time range, there are five discrete parts. Before the start, the start, after the start and before the end, the end, and after the end. We need to be able to talk about any of these five parts in sequence. If we label the parts A, B, C, D and E, we need to be able to talk about:
- A
- AB
- ABC
- ABCD
- ABCDE
- B
- BC
- BCD
- BCDE
- C
- CD
- CDE
- D
- DE
- E
I'm going to reorganize the remaining acts, and show how they relate to temporal comparisons in the following diagram:

Each of these defines a time range related to a target act. We can indicate that the start of the source act occurs within each of these ranges, or the end of the source act occurs within them to define some useful relationships. The names of these relationships would be something like SAS or EAS to represent Start after Start, or End after Start. That's nice because those are already HL7 vocabulary terms. So, now we can apply S and E to each of the above, and get 28 relationships. Hmm, this is a dead end isn't it. After all, didn't we want something smaller than 24?
It gets worse. If you've been swift, you might also note that there are some tests where you want to test both start and end of the source act. The existing OVERLAP, DURING and CONCURRENT are examples of temporal relationships that do this. So now we are up to 31 or more. Yech.
I'm sorry to report, it doesn't get better (at least yet). After some more digging, I found a paper (which I should have looked for first). James F. Allen published a paper in 1983 that reports that there are 213 = 8192 possible relationships that can be described between two definite intervals. Dr. Thomas Alspaugh provides a great explanation of Allen's paper. You should probably read that summary to understand the rest of this post.
Dr. Alspaugh explains that there are 13 basic relationships between two intervals. These 13 basic relationships are distinct (meaning each can be distinguished from the other), exhaustive (because the relationship between any two intervals A and B can always be identified as following one of these patterns), and is purely qualitative.
Where things get interesting in Allen's algebra is when Alspaugh produces a table that shows what happens when you "compose" a relationship. Composition of a relationship describes the how to compute the relationship r.s that between A and C, when A r B and B s C. As it turns out, there are 27 "composite" relations when you perform composition over the original set of 13 basic relationships.
So, I looked over the 27 different relationships, and this is what I found:
- One of the resulting relationships (full), is true for all intervals, and so is not worth addressing.
- Ten of the relationships already existed in the HL7 ActRelationshipTemporallyPertains Value Set.
- Only one of the relationships in the HL7 ActRelationshipTemporallyPertains Value set (Ends After Start) doesn't appear in the list of 27 relationships generated through composition (its inverse doesn't appear in either place).
Then I went back to the original discussion to see whether I'd been able to, using this method, match the requirements. There are two terms in NQF's Quality Data Model which aren't covered in the current vocabulary.
Starts before or during
A relationship in which the source act's effective time starts before the start of the target or starts during the target’s effective time. An Act is defined by HL7 as: “A record of something that is being done, has been done, can be done, or is intended or requested to be done.”
Ends before or during
A relationship in which the source act terminates before the target act terminates.
The challenge with these two is that they alter the meaning of during in the use of the term for "Starts Before or During". According to HL7, DURING as a vocabulary term means wholly contained within the time period of the target. So, Starts During would mean that the start time is bounded by the range of (target.start through target.end), using the non-inclusive forms of the boundaries.
What NQF did was redefine during so that an event (e.g., pacemaker present or diagnosis occured) would be considered to be in the measure period even if the event occured on 20121231. Why? Because, like just about everyone else (including me until Grahame corrected us all), we didn't know how to record the time boundary correctly. Remember the proper way to bound a time expression lasting one year is [20120101, 20130101). This means: Starting on January 1st of 2012 [inclusive], up to, but no including January 1st of the following year.
So, let's go back and fix the definition of Starts before or During so that it could be changed. Now it is simply "Starts before End." Surely that code is present? Actually, it isn't. And similarly, Ends before or during becomes Ends before End (EBE).
And so, the two codes we need to add to the HL7 Vocabulary to support everything that's been asked of for HQMF are SBE (Starts before End) and EBE (Ends before End). Which puts us back to the original 12 operators that I started with in this post. And the realization that there are 8180 more relationships that we cannot handle simply, and likely don't need to, and that there are quite a few different ways to look at temporal relationships.
It seems that we don't need to worry to much about the differences between < and <= after all. Especially if we can readily control one of the boundaries to make sure it is open or closed as necessary.
There's probably a whole post in this on the proper handling of intervals in software in general. But I'll save that for a later date. I have a harmonization proposal to finish.
-- Keith
Starts before or during
A relationship in which the source act's effective time starts before the start of the target or starts during the target’s effective time. An Act is defined by HL7 as: “A record of something that is being done, has been done, can be done, or is intended or requested to be done.”
- A pacemaker is present at any time starts before or during the measurement period: [Diagnosis active: pacemaker in situ] starts before or during [measurement period]
- A condition [diagnosis] that starts before or during [measurement end date], that means the diagnosis occurred any time before the measurement end date including the possibility that the diagnosis was established on the measurement end date itself.
Ends before or during
A relationship in which the source act terminates before the target act terminates.
- To state that intravenous anticoagulant medication is stopped before inpatient hospital discharge: [Medication administered: anticoagulant medication (route = IV)] ends before or during [Encounter: encounter inpatient]
The challenge with these two is that they alter the meaning of during in the use of the term for "Starts Before or During". According to HL7, DURING as a vocabulary term means wholly contained within the time period of the target. So, Starts During would mean that the start time is bounded by the range of (target.start through target.end), using the non-inclusive forms of the boundaries.
What NQF did was redefine during so that an event (e.g., pacemaker present or diagnosis occured) would be considered to be in the measure period even if the event occured on 20121231. Why? Because, like just about everyone else (including me until Grahame corrected us all), we didn't know how to record the time boundary correctly. Remember the proper way to bound a time expression lasting one year is [20120101, 20130101). This means: Starting on January 1st of 2012 [inclusive], up to, but no including January 1st of the following year.
So, let's go back and fix the definition of Starts before or During so that it could be changed. Now it is simply "Starts before End." Surely that code is present? Actually, it isn't. And similarly, Ends before or during becomes Ends before End (EBE).
And so, the two codes we need to add to the HL7 Vocabulary to support everything that's been asked of for HQMF are SBE (Starts before End) and EBE (Ends before End). Which puts us back to the original 12 operators that I started with in this post. And the realization that there are 8180 more relationships that we cannot handle simply, and likely don't need to, and that there are quite a few different ways to look at temporal relationships.
It seems that we don't need to worry to much about the differences between < and <= after all. Especially if we can readily control one of the boundaries to make sure it is open or closed as necessary.
There's probably a whole post in this on the proper handling of intervals in software in general. But I'll save that for a later date. I have a harmonization proposal to finish.
-- Keith




