One of the things that you learn about in Computer Science is the use of context free grammars. There is a good deal of research on making highly efficient parsers for these grammars. However, anyone who deals with real language also understands that there are parts of language that are highly context sensitive, and that in fact, is one of the reasons why natural language is and can be so much more expressive that computer languages. It can also be more ambiguous, which is yet another challenge.
In the HL7 RIM, and in CDA Templates, we've taken the approach that what you say and what you do is not affected by context. So, a problem, is a problem, is a problem, no matter where you find it. And the semantics used to communicate it, and the templates used to constrain it are consistent across many implementations.
But when we go to create an implementation guide for cancer treatment plan, or HIV services, quite often, those very general sections we described in a general way now need to be specialized. So now we wind up with specialized templates for the Breast Cancer Problems Section appearing in a Breast Cancer Treatment plan, or an HIV Problems Section specialized for an HIV Services document.
And the HIV problems section doesn't conform and cannot be used within the Breast Cancer problems section, and vise verse. We could proliferate these context dependent specializations of the problem section, but I'm playing around with another idea.
What if instead, we developed some context sensitive templates. Here's an example of one for a Breast Cancer Treatment Plan:
Breast Cancer Treatment Plan:
1. In a breast cancer treatment plan, the problems section will include BCTS specific entries for problems relevant to Breast Cancer Treatment.
2. In a breast cancer treatment plan, the encounters appearing in the encounters section may include a reason for hospitalization entry that specifies that the reason is due to toxicity.
These are just a couple of examples. The constraints themselves are attached to the breast cancer treatment plan document, and add to existing constraints of existing sections.
This is all very computable, and achieves the same goals, but it has a couple of added benefits:
It begins to attach context specific constraints to a higher level element defining the context, the document (remember that context is one of the six properties of a CDA document). I've been tossing this idea around for quite some time. The examples I gave above are derived from real work going on in HL7 ballots. I like the idea that we could say: In this context, we need information about X, Y and Z. And from a healthcare perspective, that is actually a quite useful piece of clinical knowledge. That X, Y, and Z are important in a particular context probably remains true where-ever that context exists. So even though we start off with a context of "Breast Cancer Treatment Plan", we could probably later rationalize that to cases of "Patients with Breast Cancer", and various flavors of that.
Then, the context drives the documentation, and when that happens, what you have is clearly an instance of clinical decision support. It's worth looking into.
Keith
Monday, April 29, 2013
Friday, April 26, 2013
An XML Book for non-Geeks
In the preface of The CDA Book, I insist that you must have at least a basic understanding of XML technologies in order to fully understand the HL7 CDA Standard. While I was in Saudi Arabia recently, a Health Informaticist with an interest in CDA asked me to recommend an XML book. He isn't a software engineer, but wanted to quickly develop the needed expertise in XML in order to better utilize The CDA Book.
I have numerous XML books on my shelf, as well as many SGML books. But my tastes are not what I think he needed. Nor do I think they are what many clinical or management folks need either. What they want is enough to understand what the technology can do, with enough examples and pointy brackets to explain what is needed, but not so technically overwhelming as to frighten them away.
 For the non-technical I'd recommend a book that was written in 2002 and still has valuable content even now, more than a decade later. It's not one of those 500 page or 1000 page tomes that are also useful as a hammer or a booster chair, nor is it one of those dumbed down, Dummy or Idiot titles that I really don't care for. The title is XML Pocket Consultant, published by Microsoft.
For the non-technical I'd recommend a book that was written in 2002 and still has valuable content even now, more than a decade later. It's not one of those 500 page or 1000 page tomes that are also useful as a hammer or a booster chair, nor is it one of those dumbed down, Dummy or Idiot titles that I really don't care for. The title is XML Pocket Consultant, published by Microsoft.
The book is divided into four parts, each part including from 2 to 6 chapters. Part I covers XML. Part II DTD's (skip that) and Namespaces (read that). Part III is XML Schema, and Part IV is XSLT and XPath. It's a handy book for me because it goes into enough detail that I can use it as a pocket reference book, but it is also good book for non-technical folk because chapters are fairly short (20-40 pages), and each chapter provides a good overview of a single topic that can be easily digested.
This book won't make you an XML expert, but it may make you look like one to your colleagues, and it is a book that at least one expert (me) still uses.
I have numerous XML books on my shelf, as well as many SGML books. But my tastes are not what I think he needed. Nor do I think they are what many clinical or management folks need either. What they want is enough to understand what the technology can do, with enough examples and pointy brackets to explain what is needed, but not so technically overwhelming as to frighten them away.
The book is divided into four parts, each part including from 2 to 6 chapters. Part I covers XML. Part II DTD's (skip that) and Namespaces (read that). Part III is XML Schema, and Part IV is XSLT and XPath. It's a handy book for me because it goes into enough detail that I can use it as a pocket reference book, but it is also good book for non-technical folk because chapters are fairly short (20-40 pages), and each chapter provides a good overview of a single topic that can be easily digested.
This book won't make you an XML expert, but it may make you look like one to your colleagues, and it is a book that at least one expert (me) still uses.

Thursday, April 25, 2013
Wish me Luck
What can one person do? Quite a bit. Have you ever seen Regina Holliday's artwork, or listen to ePatient Dave talk?
My own "pet project" is Health System Literacy Education. I was inspired by what I could teach my youngest daughter to develop an outline for the content. I worked within my town last year on a health literacy project sponsored by one of the community grants made available through my community health network.
Now it is time to put the grant together. This morning I took a couple of hours off my day job to talk with other CHNA members about should go in the proposal. This afternoon I talk to my local head of public health who has also expressed interest. And this evening I go (with my eldest daughter) in battle gear to an information session for proposal writers to drum up support.
Last weekend my eldest and I spoke to a number of folks about what needs to go into the educational content, and drummed up some content experts to help develop materials.
I don't know what will happen, but already I've drummed up just enough excitement to see this idea move on to the next stage. Wish me luck.
Oh, and if you want to help with content, or support, or anything else (even just to wish me luck), drop me a message or comment below.
My own "pet project" is Health System Literacy Education. I was inspired by what I could teach my youngest daughter to develop an outline for the content. I worked within my town last year on a health literacy project sponsored by one of the community grants made available through my community health network.
Now it is time to put the grant together. This morning I took a couple of hours off my day job to talk with other CHNA members about should go in the proposal. This afternoon I talk to my local head of public health who has also expressed interest. And this evening I go (with my eldest daughter) in battle gear to an information session for proposal writers to drum up support.
{kind=link}
Last weekend my eldest and I spoke to a number of folks about what needs to go into the educational content, and drummed up some content experts to help develop materials.
I don't know what will happen, but already I've drummed up just enough excitement to see this idea move on to the next stage. Wish me luck.
Oh, and if you want to help with content, or support, or anything else (even just to wish me luck), drop me a message or comment below.
Wednesday, April 24, 2013
Finally, a new definition of Interoperability
And do you know how I respond to this? I'm so very glad you figured that out. Now that you understand it, can we get on to some real work?
It's good that various organizations take the time to define what they are after. And there is value in looking at things over again from time to time to see what's changed. And it is also a good thing to get everyone on the same page. And I'm sure there was some good reason for this effort in 2013. But it doesn't excite me in the least.
This project has been done, and redone, and frankly, overdone, by AHIMA (2006), HIMSS (2005), HL7 (2007), NAHIT (2005) and ONC and various others over the past decade. For those of us who have been working in the field for the last decade or so are just a bit bored about new definitions for old concepts.
Was some or all of the prior work even considered? Unfortunately I don't know. The really sad part here is that I could have even helped out with these observations ahead of time, if I just had more time to pay attention.
One thing I truly find painful is when old definitions for old concepts are simply renamed. What IEEE used to call Interoperability in 1990 is what HIMSS calls Semantic Interoperability in 2013.
The IEEE definition published the most oft-quoted definition of Interoperability I've seen:
Would you like to know what the IEEE Standards Glossary says in 2013?
Don't get me wrong, getting folks to agree on what you are doing is good. Just don't expect me to get excited about redoing work that is already more than two decades old, and that comes to the same conclusions. It's simply not notable.
To do it again? Somehow I think there are better uses of our time, and wonder why nobody brought that up. Perhaps it helped to educate the new crop of freshman. I don't know, and just cannot figure this one out.
-- Keith
It's good that various organizations take the time to define what they are after. And there is value in looking at things over again from time to time to see what's changed. And it is also a good thing to get everyone on the same page. And I'm sure there was some good reason for this effort in 2013. But it doesn't excite me in the least.
This project has been done, and redone, and frankly, overdone, by AHIMA (2006), HIMSS (2005), HL7 (2007), NAHIT (2005) and ONC and various others over the past decade. For those of us who have been working in the field for the last decade or so are just a bit bored about new definitions for old concepts.
Was some or all of the prior work even considered? Unfortunately I don't know. The really sad part here is that I could have even helped out with these observations ahead of time, if I just had more time to pay attention.
One thing I truly find painful is when old definitions for old concepts are simply renamed. What IEEE used to call Interoperability in 1990 is what HIMSS calls Semantic Interoperability in 2013.
The IEEE definition published the most oft-quoted definition of Interoperability I've seen:
... the ability of two or more systems or components to exchange information and to use the information that has been exchanged.and comes from the IEEE Standards Dictionary, a compendium of glossaries published in 1990 (and is referenced from the HIMSS definition).
Would you like to know what the IEEE Standards Glossary says in 2013?
Ability of a system or a product to work with other systems or products without special effort on the part of the customer. Interoperability is made possible by the implementation of standards.Quite different phrasing, but much the same meaning to those of us who work in the space. To those who don't work in the space, this is much clearer. The without special effort on the part of the consumer is implied in the previous definition. Here it is made explicit, and that is quite useful. Was that even referenced?
Don't get me wrong, getting folks to agree on what you are doing is good. Just don't expect me to get excited about redoing work that is already more than two decades old, and that comes to the same conclusions. It's simply not notable.
To do it again? Somehow I think there are better uses of our time, and wonder why nobody brought that up. Perhaps it helped to educate the new crop of freshman. I don't know, and just cannot figure this one out.
-- Keith
Tuesday, April 23, 2013
Wouldn't it be interesting if ...
"Wouldn't it be interesting if ..." the tweet starts. And continues: "... there were a standards development organization founded/ran by patients?"
There is an idea in here that is absolutely right, and an implementation that isn't ideal.
Let's start with what is right. What is right is that patients are the ultimate consumer of what we do in Health IT, and they absolutely need to be at the table and well represented.
What is wrong is simply that standards are about consensus among all stakeholders. Any standards process that gives one body more representation or control than another is broken, even if it does so with the best of intentions.
I've been involved with standards efforts where one stakeholder group had more power than others (even today this is still true in S&I Framework -- just ask yourself who sets the agenda), and can tell you that it can be challenging. Been there, done that (on both sides). Certainly it is "comfortable" to be with the stakeholder group in power, but it doesn't lead to the best outcomes for all.
The harder thing, but probably more useful to do is to become influential in an existing community. Been there, done that. If you can manage it, it results in more success. Rather than attempting to compete on dramatically unequal footing, what you wind up doing is co-opting the existing community on your own terms. You have to start softer. You aren't trying to change the world all at once (see reboot or re-boot). Just trying to get the direction shifted a little bit, then a bit more. Until eventually, well, you get the idea.
This is happening to some degree inside HL7. There are people who are seeking change, and making it happen (e.g., Mobile Health, Quality, Free IP and other initiatives), bringing in other stakeholders to help. The balance of power is shifting. Directions are changing.
The biggest challenge for patients in all of this is understanding how they/we can participate. Some are techno-geeky, like me, but with non-healthcare backgrounds (also how I started). Others are non-techno geeky. Others have a healthcare background. And others, are simply just frustrated with the way things work today.
The biggest challenge for organizations wanting to engage patients is figuring out what it means to be a representative of that stakeholder group. The usual classifications here don't necessarily work. The minimal requirements for classification of stakeholders (according to section 2.3 of ANSI Essential Requirements) is:
There is an idea in here that is absolutely right, and an implementation that isn't ideal.
Let's start with what is right. What is right is that patients are the ultimate consumer of what we do in Health IT, and they absolutely need to be at the table and well represented.
What is wrong is simply that standards are about consensus among all stakeholders. Any standards process that gives one body more representation or control than another is broken, even if it does so with the best of intentions.
I've been involved with standards efforts where one stakeholder group had more power than others (even today this is still true in S&I Framework -- just ask yourself who sets the agenda), and can tell you that it can be challenging. Been there, done that (on both sides). Certainly it is "comfortable" to be with the stakeholder group in power, but it doesn't lead to the best outcomes for all.
The harder thing, but probably more useful to do is to become influential in an existing community. Been there, done that. If you can manage it, it results in more success. Rather than attempting to compete on dramatically unequal footing, what you wind up doing is co-opting the existing community on your own terms. You have to start softer. You aren't trying to change the world all at once (see reboot or re-boot). Just trying to get the direction shifted a little bit, then a bit more. Until eventually, well, you get the idea.
This is happening to some degree inside HL7. There are people who are seeking change, and making it happen (e.g., Mobile Health, Quality, Free IP and other initiatives), bringing in other stakeholders to help. The balance of power is shifting. Directions are changing.
The biggest challenge for patients in all of this is understanding how they/we can participate. Some are techno-geeky, like me, but with non-healthcare backgrounds (also how I started). Others are non-techno geeky. Others have a healthcare background. And others, are simply just frustrated with the way things work today.
The biggest challenge for organizations wanting to engage patients is figuring out what it means to be a representative of that stakeholder group. The usual classifications here don't necessarily work. The minimal requirements for classification of stakeholders (according to section 2.3 of ANSI Essential Requirements) is:
- Producer
- User
- General Interest
A fourth category that often shows up is "government", from the perspective of regulators or imposers of the standard. Producers and users (usually purchasers) often have an obvious financial stake that makes it possible for them to obtain funding to participate in the development of standards. Government too has a way to fund its participation. But patients most often fall into the "general interest" category, and from that perspective, often don't have a funding source for participation.
More often than not, other non-profit organizations devoted to representation of patients or consumers will often show up, and do have funding. But these organizations aren't the same as the stakeholders (and in fact, there are SOME I would NOT have represent me, because I don't agree with their perspective).
I like the idea of patient scholarships, but it isn't clear how that would work, or what the proper governance is.
The final challenge is how to address the fact that we can all fit ourselves (as I did in this post on Patient-Centric Health IT) into the "General Interest" category. While each of us can fit into that category, we have different perspectives based on our involvements as producers or users or other categories as well. And we all balance those differently. General interest in this list is almost an "other" category, as in Not Otherwise Specified.
What may be important are the various "declarations" that a participant can make:
- Do you spend money or resources to implement or conform to the standard?
- Do you receive money or resources to implement or conform to the standard?
- Are you in a position to require use of those standards in a particular market?
I find it difficult for many who would argue that they are representatives of patients who can say yes to either 1 or 2 as being strictly representative of the "patient" stakeholder group.
So, wouldn't it be interesting if, we were to find a way to enable patients more participation in the development of standards? Certainly it would be. But, I think the journey will possibly be more interesting than the destination.
Monday, April 22, 2013
Our Foo is Stronger
Headed to Boston for #Healthfoo was how the FB post read.
"Dang, I guess I wasn't invited this year," I thought to myself "again."
And this time there was nobody there to lobby for me to attend as happened last year.
Because by the time it started, they were already talking about canceling it. And by Friday afternoon it was cancelled, because Boston was either "locked down" or "sheltering in place" depending on whose spin you want to put on it.
But the next FB post I saw said something different: "Need help planning unconference."
So, I responded Friday night, and found out Saturday morning that Regina, Ted, David, Fred and many others were planning things out over breakfast a few hours from when I read the post. I dropped my daughter off at her horse-back riding, did the weeks shopping ultra-fast. Ran home and off-loaded it, and then bundled the rest of my family (who all wanted to at least meet Regina) into the car, where we then went back to pick up my eldest daughter from her horseback riding lesson, and threw clean clothes at her.
And we trucked on through Boston Saturday morning to meet up with the Health Foo crowd. It was a bit odd, see a caravan of eight police cars and military HUMVEE convoying from Huntington Avenue to Mass ave with sirens blaring ("Prisoner transport?" I thought to myself), or to see a second hummer sitting on Mass Ave at Boylston Street with a gun mount atop it.
We got to the breakfast venue only to see that the group was splitting, given the lack of space and quiet in venue #1. I left my eldest in the charge of Regina and the rest of the family joined the remaining crowd to plan things out. Discovering that the event had been cancelled actually made it possible for my eldest daughter and I to attend it. We could only spend Saturday (Sunday being the day we were to celebrate my youngest's 11th birthday). My wife and youngest daughter headed home after breakfast.
After our "second breakfast" (at least for my eldest and I who had already been up since 6), we met up for coffee again at a nearby hotel, and then headed over to MIT to hold the un-foo, or as it was later to be called, the foo-foo. We spent about 6 hours unconferencing in MIT space (made available by @littledevices), before the two of us headed home on the Red Line.
For more on what happened, see posts by Ted and David, and especially check out Ted's photo-stream.
On our way home, my daughter and I stopped to pay homage at the shrine that sprung up on campus for the MIT policeman who was shot and killed in the craziness on Friday.
As others have said, and I simply repeat: Our Foo is strong.
"Dang, I guess I wasn't invited this year," I thought to myself "again."
And this time there was nobody there to lobby for me to attend as happened last year.
Because by the time it started, they were already talking about canceling it. And by Friday afternoon it was cancelled, because Boston was either "locked down" or "sheltering in place" depending on whose spin you want to put on it.
But the next FB post I saw said something different: "Need help planning unconference."
So, I responded Friday night, and found out Saturday morning that Regina, Ted, David, Fred and many others were planning things out over breakfast a few hours from when I read the post. I dropped my daughter off at her horse-back riding, did the weeks shopping ultra-fast. Ran home and off-loaded it, and then bundled the rest of my family (who all wanted to at least meet Regina) into the car, where we then went back to pick up my eldest daughter from her horseback riding lesson, and threw clean clothes at her.
And we trucked on through Boston Saturday morning to meet up with the Health Foo crowd. It was a bit odd, see a caravan of eight police cars and military HUMVEE convoying from Huntington Avenue to Mass ave with sirens blaring ("Prisoner transport?" I thought to myself), or to see a second hummer sitting on Mass Ave at Boylston Street with a gun mount atop it.
We got to the breakfast venue only to see that the group was splitting, given the lack of space and quiet in venue #1. I left my eldest in the charge of Regina and the rest of the family joined the remaining crowd to plan things out. Discovering that the event had been cancelled actually made it possible for my eldest daughter and I to attend it. We could only spend Saturday (Sunday being the day we were to celebrate my youngest's 11th birthday). My wife and youngest daughter headed home after breakfast.
For more on what happened, see posts by Ted and David, and especially check out Ted's photo-stream.
On our way home, my daughter and I stopped to pay homage at the shrine that sprung up on campus for the MIT policeman who was shot and killed in the craziness on Friday.
As others have said, and I simply repeat: Our Foo is strong.
Friday, April 19, 2013
Reboot or Re-boot?
I've heard the phrase "reboot" used several times recently. A couple of days ago it was in reference to the HITECH act and Meaningful Use. Today it was about the healthcare system [sic], and at other times, I've heard the phrased used with respect to interoperability and standards.
Rarely is a reboot possible. Once a path is started down, there is simply too much momentum to shut it down and start over. As much as I would LOVE to redesign our healthcare system from scratch, I realize that existing momentum is greater than my capability to stop and restart the system. Also, unless you change something, reboot likely doesn't fix the problem. I can count on one hand the number of times rebooting fixed my networking issues, and it never works for the cable-guys when I call them (because if it would have, I'd have already done it).
In mathematics, complex optimization problems are often challenged by getting stuck in local minima. Various solutions to this problem usually involve successively larger and larger kicks. This often works to dislodge the system from a local minima and enables discovery of a better solution. Successive jolts are also useful when done in a repeated and rhythmic fashion (developing a harmonic). Ever rocked a stuck car out of an icy or otherwise slippery hole?
So, it's not "Reboot" as in start over again. By the time you've figured out that you are stuck with a non-optimal solution, the opportunity to start over probably doesn't exist. Rather, "Re-boot", as in "Kick it Harder". That just might work. Or you could end up breaking it altogether (which according to my Stage manager wife, means that it just needed replacing anyway), or you could just wind up with a broken toe. All of these are possible outcomes when you attempt to "re-boot". It's never a guarantee of success. The critical challenge with kick it again, or kick it harder, is figuring out where and how hard, and in what direction to apply that impulse.
 So, if your advice is to "reboot", or even "re-boot", think again. What is the right direction and force to apply to that kick that will dislodge the system and move it in the right direction. It's pretty darn easy to say kick it again. The really hard part is to say "kick it right here". And that is what differentiates an expert from a novice.
So, if your advice is to "reboot", or even "re-boot", think again. What is the right direction and force to apply to that kick that will dislodge the system and move it in the right direction. It's pretty darn easy to say kick it again. The really hard part is to say "kick it right here". And that is what differentiates an expert from a novice.
Keith
Rarely is a reboot possible. Once a path is started down, there is simply too much momentum to shut it down and start over. As much as I would LOVE to redesign our healthcare system from scratch, I realize that existing momentum is greater than my capability to stop and restart the system. Also, unless you change something, reboot likely doesn't fix the problem. I can count on one hand the number of times rebooting fixed my networking issues, and it never works for the cable-guys when I call them (because if it would have, I'd have already done it).
In mathematics, complex optimization problems are often challenged by getting stuck in local minima. Various solutions to this problem usually involve successively larger and larger kicks. This often works to dislodge the system from a local minima and enables discovery of a better solution. Successive jolts are also useful when done in a repeated and rhythmic fashion (developing a harmonic). Ever rocked a stuck car out of an icy or otherwise slippery hole?
So, it's not "Reboot" as in start over again. By the time you've figured out that you are stuck with a non-optimal solution, the opportunity to start over probably doesn't exist. Rather, "Re-boot", as in "Kick it Harder". That just might work. Or you could end up breaking it altogether (which according to my Stage manager wife, means that it just needed replacing anyway), or you could just wind up with a broken toe. All of these are possible outcomes when you attempt to "re-boot". It's never a guarantee of success. The critical challenge with kick it again, or kick it harder, is figuring out where and how hard, and in what direction to apply that impulse.
Keith
Thursday, April 18, 2013
MDHT enables IHE PCC and HL7 CCDA Harmonization
One of the things I really like about MDHT is that it gives me programmatic access to the information model associated with templates. The access is through the Eclipse Modeling Framework (EMF), and the EMF Core classes (eCore).
I've downloaded the MDHT All-In-One release, and started writing some Java code against the Java classes created by MDHT to represent the various templates. I am using eCore's introspection capabilities to enable comparision between the IHE PCC Templates in final text, and the HL7 Consolidation Guide templates.
MDHT delivers the two different workspaces, one including CCD, IHE and HITSP templates, and another including the HL7 Consolidation guide templates. I simply imported the projects from the former workspace into the latter one, so I could work with both. If you go to do that yourself, you will note that you cannot copy some of the projects over (because of name clashes). Don't worry about those, as they are the base CDA and HL7 datatypes and RIM models that are in shated in common.
What I wanted to do with this data was to be able to compare the differences between the IHE and CDA Consolidation templates. The C-CDA comes with a template crosswalk (see the section on Template ID Changes in Appendix B in the guide) that enables this. MDHT has a template comparison facility (which I'd have to use manually). I had a challenge making that template comparison work, because I didn't have all the right projects open (I'm not sure why the MDHT comparison has that requirement). But I was eventually was able to get it to work with the help of Sean Muir.
That facility compares the templates based on their general structure. However, I needed my comparison to be based on the deep structure as resolved through closure over all templates. In other words, if template A and template B had the same constraint on an attribute, either directly or indirectly through another template, then I considered that to be no difference, regardless of the source of the constraint. So, it was time to write some code.
The next challenge I had was configuring my project to have access to the eCore libraries that all my imports worked. I did what just about everyone else does, looked at what worked elsewhere and copied it. I created my the build path from what appeared in the org.openhealthtools.mdht.uml.cda.ihe project (where the IHE template classes were created), and I also included the various projects. I probably have too much included, but will not both cleaning that up until later. What I know is that I have what I need, and I'll figure out what I don't need later.
So now I get to go spelunking through the models, to figure out how the various relationships are recorded in eCore. Once I have that figured out, I should be able to compute the intersection of common constraints between them. That becomes the basis for version 2 of the IHE templates. There will be some constraint that IHE won't give up even though they've been dropped or weakened in C-CDA. It will be very easy to identify those as well.
This should be fun. It's a good thing I can automate this, because I have to have the basic framework for Volume 2 ready in just a couple of weeks.
I've downloaded the MDHT All-In-One release, and started writing some Java code against the Java classes created by MDHT to represent the various templates. I am using eCore's introspection capabilities to enable comparision between the IHE PCC Templates in final text, and the HL7 Consolidation Guide templates.
MDHT delivers the two different workspaces, one including CCD, IHE and HITSP templates, and another including the HL7 Consolidation guide templates. I simply imported the projects from the former workspace into the latter one, so I could work with both. If you go to do that yourself, you will note that you cannot copy some of the projects over (because of name clashes). Don't worry about those, as they are the base CDA and HL7 datatypes and RIM models that are in shated in common.
What I wanted to do with this data was to be able to compare the differences between the IHE and CDA Consolidation templates. The C-CDA comes with a template crosswalk (see the section on Template ID Changes in Appendix B in the guide) that enables this. MDHT has a template comparison facility (which I'd have to use manually). I had a challenge making that template comparison work, because I didn't have all the right projects open (I'm not sure why the MDHT comparison has that requirement). But I was eventually was able to get it to work with the help of Sean Muir.
That facility compares the templates based on their general structure. However, I needed my comparison to be based on the deep structure as resolved through closure over all templates. In other words, if template A and template B had the same constraint on an attribute, either directly or indirectly through another template, then I considered that to be no difference, regardless of the source of the constraint. So, it was time to write some code.
The next challenge I had was configuring my project to have access to the eCore libraries that all my imports worked. I did what just about everyone else does, looked at what worked elsewhere and copied it. I created my the build path from what appeared in the org.openhealthtools.mdht.uml.cda.ihe project (where the IHE template classes were created), and I also included the various projects. I probably have too much included, but will not both cleaning that up until later. What I know is that I have what I need, and I'll figure out what I don't need later.
So now I get to go spelunking through the models, to figure out how the various relationships are recorded in eCore. Once I have that figured out, I should be able to compute the intersection of common constraints between them. That becomes the basis for version 2 of the IHE templates. There will be some constraint that IHE won't give up even though they've been dropped or weakened in C-CDA. It will be very easy to identify those as well.
This should be fun. It's a good thing I can automate this, because I have to have the basic framework for Volume 2 ready in just a couple of weeks.
Tuesday, April 16, 2013
Lies, Damn Lies and Politics
Six GOP Senators call for overview of Meaningful Use EHR incentive program was the tweet. It referenced this link. Which then referred to this report by Senators Thune, Alexander, Roberts, Burr, Coburn and Enzi.
To be clear, I'm a card carrying Liberal, and the six Republican Senators whose names are on this report voted against ARRA and HITECH. It's already pretty clear that we'd disagree on some things. Yet, reading through the report, I find many statements I could agree with. There were many others which I was quite cautious about, given that the Senators compared apples to oranges.
What annoyed me most were the at least two very clear misstatements of fact. Given what the senators (or their ghostwriters) should know, I can call nothing other than an outright lie. If there's something I hate worse than BS in headlines, it is outright lies in reports like this one.
Lie #1: "None of the required core or menu objectives in Stage 2 requires communication with other health care providers." (page 11, paragraph 2).
In the meaningful incentive regulation:
Lie #2: Even worse, on top of this, providers will be penalized for not all reaching a common milestone (page 13, paragraph 1)
CMS has only stated that there will be penalties for providers not achieving meaningful use after 2015. It has not required providers to achieve the same stage of meaningful use in the incentives regulation.
Not on top of the facts #1: One of the key program vulnerabilities of the current HITECH program is that providers simply self report to CMS that they have met meaningful use criteria in order to receive federal funds. This is a startling lack of program integrity.
Indeed. But the Senators only have congress to blame for this misstep. I quote below from HITECH Law:
A true statement, but not the most current appreciation of the state of affairs regarding prepayment reviews, which CMS is conducting according to this report.
Useless section #1: Long-Term Questions on Data Security and Patient Safety Remain
Of course they do. Yet there is not a single actionable observation or statement in this section. FUD anyone?
Disingenuous warping of data #1 [emphasis mine]: According to the Government Accountability Office, participation for 2011, the most recent year data is available from an entity outside of the U.S. Department of Health and Human Services, shows that participation in the program is low.
Really? You want to rely on two year old data to assess where the program is now? With that kind of speed in analysis, it really could take us 10 to 15 years to get there. While I appreciate the Senators' caution, I'll cite their own words back at them: "... with the Medicare program facing insolvency it is unacceptable for CMS to wait for two years on this potential threat" (page 16).
The Real Shame
There are so many other problems in the report that it's easy to ignore everything else it has to say. Yet some of the critiques are worth discussion. And that is the real loss, but only if the Senators had truly wanted to have a dialogue as claimed. Unfortunately, circumstantial evidence seems to indicate otherwise.
To be clear, I'm a card carrying Liberal, and the six Republican Senators whose names are on this report voted against ARRA and HITECH. It's already pretty clear that we'd disagree on some things. Yet, reading through the report, I find many statements I could agree with. There were many others which I was quite cautious about, given that the Senators compared apples to oranges.
What annoyed me most were the at least two very clear misstatements of fact. Given what the senators (or their ghostwriters) should know, I can call nothing other than an outright lie. If there's something I hate worse than BS in headlines, it is outright lies in reports like this one.
Lie #1: "None of the required core or menu objectives in Stage 2 requires communication with other health care providers." (page 11, paragraph 2).
In the meaningful incentive regulation:
495.6 (j)(14)(i) Objective. The EP who transitions their patient to another setting of care or provider of care or refers their patient to another provider of care provides a summary care record for each transition of care or referral.
495.6 (k)(1)(i) Objective. Imaging results consisting of the image itself and any explanation or other accompanying information are accessible through Certified EHR Technology.
495.6 (l)(11)(i) Objective. The eligible hospital or CAH that transitions their patient to another setting of care or provider of care or refers their patient to another provider of care provides a summary care record for each transition of care or referral.
495.6 (m)(2)(i) Objective. Imaging results consisting of the image itself and any explanation or other accompanying information are accessible through Certified EHR Technology.
495.6 (m)(6)(i) Objective. Provide structured electronic lab results to ambulatory providers.They missed not just one, but five separate interoperability requirements that require communication with other healthcare providers (and I haven't included a single of the "communicate with public health" requirements which also have interoperability requirements).
Lie #2: Even worse, on top of this, providers will be penalized for not all reaching a common milestone (page 13, paragraph 1)
CMS has only stated that there will be penalties for providers not achieving meaningful use after 2015. It has not required providers to achieve the same stage of meaningful use in the incentives regulation.
Not on top of the facts #1: One of the key program vulnerabilities of the current HITECH program is that providers simply self report to CMS that they have met meaningful use criteria in order to receive federal funds. This is a startling lack of program integrity.
Indeed. But the Senators only have congress to blame for this misstep. I quote below from HITECH Law:
(i) IN GENERAL.—A professional may satisfy the demonstration requirement of clauses (i) and (ii) of subparagraph (A) through means specified by the Secretary, which may include—Not on top of the facts #2: One of the most alarming findings in the OIG report is CMS’ response that, despite the OIG’s warning, it does not agree that more pre-payment review of eligibility is necessary since it could delay incentive payments.
(I) an attestation;
(II) the submission of claims with appropriate coding (such as a code indicating that a patient encounter was documented using certified EHR technology);
(III) a survey response;
(IV) reporting under subparagraph (A)(iii); and
(V) other means specified by the Secretary.
A true statement, but not the most current appreciation of the state of affairs regarding prepayment reviews, which CMS is conducting according to this report.
Useless section #1: Long-Term Questions on Data Security and Patient Safety Remain
Of course they do. Yet there is not a single actionable observation or statement in this section. FUD anyone?
Disingenuous warping of data #1 [emphasis mine]: According to the Government Accountability Office, participation for 2011, the most recent year data is available from an entity outside of the U.S. Department of Health and Human Services, shows that participation in the program is low.
Really? You want to rely on two year old data to assess where the program is now? With that kind of speed in analysis, it really could take us 10 to 15 years to get there. While I appreciate the Senators' caution, I'll cite their own words back at them: "... with the Medicare program facing insolvency it is unacceptable for CMS to wait for two years on this potential threat" (page 16).
The Real Shame
There are so many other problems in the report that it's easy to ignore everything else it has to say. Yet some of the critiques are worth discussion. And that is the real loss, but only if the Senators had truly wanted to have a dialogue as claimed. Unfortunately, circumstantial evidence seems to indicate otherwise.
A Triumph of Endurance
Yesterday was Patriot's Day. This is not just Marathon Monday, but a day where we commemorate the defiance of people who want freedom from tyranny, and a battle where the people, rather than the "trained" soldiers were victorious. Yesterday, another battle took place, with a different kind of enemy.
Yesterday's tragic events in Boston hit very close to me (fortunately, neither I nor any of my family was anywhere close to the events yesterday). I know people who run this race (all are safe). I know the area where the attacks occurred well, having worked close by. I walked this area several times a week on a regular basis over the last couple of decades. One of the hotels that was evacuated yesterday is next to the building where I used to have an office (my office is now down a flight of stairs from my kitchen). The streets where I used to walk to work are now a crime scene.
Boston is tough, and the way its people responded to the act of terrorism yesterday showed it. In videos and images, it was very clear that so many people moved to help first, rather than run away from the challenges. My children grew up through 9/11. Not only are they digital natives, but they are also much more exposed to acts of terror, horror and war than I was at the same age. But for them and for I, this is NOT the new normal. I was proud of my own children's response yesterday to this act of senseless violence. In my house yesterday, there was no fear, only sadness and anger.
I expect the people of Boston will remember what Patriot's day, and the Boston Marathon represent, a triumph of endurance by the people, and not a day to be feared. And again, as before, I expect the people to be victorious, rather than those who attacked.
My heart goes out to all those who were injured or died yesterday, and to the families of all those affected.
-- Keith
Monday, April 15, 2013
Precision is the enemy of accuracy
I'm sure to get reamed for this post, but if so, it will only prove my point unless those doing the reaming are both accurate and precise.
I've been watching the growing eterna-thread* about the proper way to record allergies, intollerances and adverse reactions over on the HL7 Patient Care list for the past few weeks. It simply raises up the same old issues, and I think we are still no closer to having a better model for recording allergies than CCD used more than six years ago.
The issues that keep coming up have to do with the "correct" way of doing things. Which as far as I can tell, no two professionals completely agree. As far as I can tell, I am actually one step ahead of many, since I don't claim to know much, whereas others who know much more disagree quite robustly.
 What seems to have been forgotten in this discussion is the difference between precision and accuracy. Current models for reporting allergies and intolerances are accurate, they just lack precision. And because they lack precision, and because healthcare professionals understand that they lack precision, the data about allergies is used appropriately.
What seems to have been forgotten in this discussion is the difference between precision and accuracy. Current models for reporting allergies and intolerances are accurate, they just lack precision. And because they lack precision, and because healthcare professionals understand that they lack precision, the data about allergies is used appropriately.
Because we can be more precise, there is a great deal of desire to do so. Being more precise gives physicians more treatment options. It enables better use of available resources. It avoids overstatement. It allows for a more precise assessment.
But, in so doing, it requires others to act with a greater degree of precision as well. I'm not so happy about providing physicians with a very precise statement of my allergies and intolerances if it means that they become paralyzed trying to understand it, or are unable to make use of it with the degree of precision and accuracy necessary.
Where we are now enables us to make a generalized statement about allergy and intolerances, and invites further exploration by the healthcare provider when greater precision is necessary. This seems to be the safest path forward. But what do I know? I'm not an expert. I just have to implement what they tell me. Once they all agree on what that is...
Keith
* An eterna-thread is a discussion thread that had been going on (or will go on) seemingly for eternity. The way I identify eterna-threads is if I can write a rule for filing it based on keywords in content.
I've been watching the growing eterna-thread* about the proper way to record allergies, intollerances and adverse reactions over on the HL7 Patient Care list for the past few weeks. It simply raises up the same old issues, and I think we are still no closer to having a better model for recording allergies than CCD used more than six years ago.
The issues that keep coming up have to do with the "correct" way of doing things. Which as far as I can tell, no two professionals completely agree. As far as I can tell, I am actually one step ahead of many, since I don't claim to know much, whereas others who know much more disagree quite robustly.
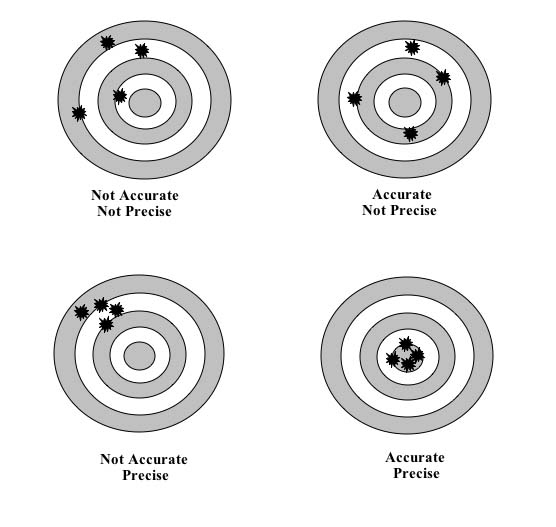
Because we can be more precise, there is a great deal of desire to do so. Being more precise gives physicians more treatment options. It enables better use of available resources. It avoids overstatement. It allows for a more precise assessment.
But, in so doing, it requires others to act with a greater degree of precision as well. I'm not so happy about providing physicians with a very precise statement of my allergies and intolerances if it means that they become paralyzed trying to understand it, or are unable to make use of it with the degree of precision and accuracy necessary.
Where we are now enables us to make a generalized statement about allergy and intolerances, and invites further exploration by the healthcare provider when greater precision is necessary. This seems to be the safest path forward. But what do I know? I'm not an expert. I just have to implement what they tell me. Once they all agree on what that is...
Keith
* An eterna-thread is a discussion thread that had been going on (or will go on) seemingly for eternity. The way I identify eterna-threads is if I can write a rule for filing it based on keywords in content.
Tuesday, April 9, 2013
Bullshit Headlines
I hate it when journalists put a bullshit headline or spin on a story to attract attention. Here are a few that caught my attention recently:
Here's the original article title with a link:
Accenture Survey Reveals Most US Doctors Believe Patients Should Help Update Their Electronic Health Records, But Shouldn’t Have Access to Their Full Record
And here's the most significant quote from the announcement:
Thank you Accenture for providing an accurate title. Unfortunately, our media seems to harp on bad news.
The good news:
The bad news? It appears that some of the media doesn't know how to make any money from good news. These headlines aren't on articles from obscure media outlets, either.
Could it be better? Damn right. But badly harping on what is bad isn't going to make it better. If you really wanted to harp on the bad parts of this news, I ask you, where is the reporting on the patient outrage at this report. Or perhaps the investigative reporting on why providers aren't offering what they say that they approve of?
Surely you could find a patient or two to interview about access to records, and the importance of it, and what we need to do to get better as a nation (if not, I can link you to a double dozen and more). Or maybe you could talk to some healthcare providers on either side of this story. Come on. Get with the program. And next time, give me some real headlines with the real news.
-- Keith
P.S. And yes, this headline is SEO optimized, just to double down on the point.
- Doctors not eager for you to touch your own health records
- Electronic Health Records: Doctors Want to Keep Patients Out
- Most U.S. Doctors Would Limit Patient EHR Access
- MOST DOCS DON’T WANT YOU TO SEE YOUR FULL ELECTRONIC MEDICAL RECORD
- Most Doctors Prefer Not Sharing Records with Patients
- Few Physicians Say Patients Should Have Full EHR Access
Here's the original article title with a link:
Accenture Survey Reveals Most US Doctors Believe Patients Should Help Update Their Electronic Health Records, But Shouldn’t Have Access to Their Full Record
And here's the most significant quote from the announcement:
A new Accenture survey shows that most US doctors (82 percent) want patients to actively participate in their own healthcare by updating their electronic health records. However, only a third of physicians surveyed (31 percent) believe their patients should have access to their full health record (see Figure 1). These findings were consistent among 3,700 doctors surveyed by Accenture in eight countries: Australia, Canada, England, France, Germany, Singapore, Spain and the United States.
Thank you Accenture for providing an accurate title. Unfortunately, our media seems to harp on bad news.
The good news:
- 4 out of 5 doctors want you to have access to update your health records,
- 96% believe patients should have some access to their record,
- and 3 in 10 believe that patients should have access to their FULL record.
The bad news? It appears that some of the media doesn't know how to make any money from good news. These headlines aren't on articles from obscure media outlets, either.
Could it be better? Damn right. But badly harping on what is bad isn't going to make it better. If you really wanted to harp on the bad parts of this news, I ask you, where is the reporting on the patient outrage at this report. Or perhaps the investigative reporting on why providers aren't offering what they say that they approve of?
Surely you could find a patient or two to interview about access to records, and the importance of it, and what we need to do to get better as a nation (if not, I can link you to a double dozen and more). Or maybe you could talk to some healthcare providers on either side of this story. Come on. Get with the program. And next time, give me some real headlines with the real news.
-- Keith
P.S. And yes, this headline is SEO optimized, just to double down on the point.
Monday, April 8, 2013
What do I need to know?
How do I get a job like yours? How did you learn how to do what you do? These are all variations of questions that I get from time to time that is a) quite complimentary, and b) extremely challenging for me to answer.
Be Passionate
Few people I know in the standards space ever planned to be where they are now. That goes for me in spades. If you had told me in my misspent youth that I'd be reading House, Senate and Conference editions of healthcare bills in the same week, or that I'd be commenting on federal regulation and be taken seriously, or that the work I'd been doing would impact as many lives as I think it does now, I'd have laughed you right out of the room. I never planned to be in this career, but once I found it, and acknowledged it as a calling, I latched onto it hard and with great passion.
That's my first tip. Be passionate about what you are doing. Being passionate is not just about loving your work, or having fun at your job, it's about taking it really seriously, and loving it at the same time, even when it sucks. If you don't love doing this work, you won't succeed in it. There will be times that what you have to do to get a job finished sucks: It may be tedious and boring, impossibly frustrating or just plain painfully unrewarding. You have to learn to take your rewards from a job successfully done, and done well, and with the impact that it can have on people. Financially, the job can be rewarding, but if financial reward is your measure of success, this job isn't for you.
Become an Expert
What do I need to learn? You need to learn something at the expert level. That requires a good deal of commitment. It's not just about spending 10,000 hours on something, but being passionate while you do it. And by something, I mean something that others will value enough to seek you out for your expertise. I can't tell you what to learn. I can tell you to pick something where people are already confused and seeking help. It's helpful to have another expert to rely on to help you out, but that isn't necessary. It's a lot easier to become first in a field of one than it is to become first in a field of 10. And if there are already 10 experts in your chosen field, branch out a bit. What good is one more expert when there are already 10?
To learn something at the expert level means that you have to understand how the parts it relies upon work together. You have to be more than a novice at XML before you will ever become an expert in CDA. If you don't understand how XML and XML Schema work, there will be things about CDA that you just won't understand. If you don't understand how a combustion engine works, you'll never become expert on motorcycles. That doesn't mean, by the way, that you need to have expert skills in the underlying components, but it might. The closer ties that the two things have, the more you need to know.
Have other Experiences
Being an expert about X is useless if you cannot apply X to problem Y. You need to learn enough about problem Y as it relates to X. I have skills in database management, natural language processing, data compression, digital signal processing, text processing, text and graphics rendering, text markup, and document analysis. Those skills were developed over a twenty year career before I ever got into CDA and Healthcare.
Some of the best CDA experts in the world got their start in SGML. At least one CDA consulting firm I know is made up of numerous people who had SGML, or similarly related skills first. CDA experience (and subsequent expertise) came with the job.
Learn something new as part of your routine. Challenge yourself. Read a book that you don't understand fully. Skip the parts you don't understand and then go back and read them again later. One of the coolest things that I love about my job is when two (or more) things I've read go click, and all of the sudden, I gain a new insight.
Develop a Network
When I work on a problem, you don't get just me. You get Glen and Charles and John and Harry and Lori and Gila and Bob and Tom and Rob and Tim and ... the rest of my network. You aren't alone, don't act that way. Call on your friends and colleagues to get their advice. Listen also to your critics as well. Then make your own judgement, and use what you found valuable. At the same time, when others call on you, offer your best efforts to help them out when you can.
The Health IT standards world may look like the good ole boy network, but it's not because the entry criteria is different. That's where being an expert is important, because experts often need other experts, and will work well with other experts they respect, even when they disagree. Some of the people I most respect in this field are ones I also have the most interesting arguments with.
Find (and Lose) a Mentor
I can count on one hand the number of mentors I've had in my life, and the number of people I've been a mentor too. It's a very special relationship, and incredibly valuable on both sides. If you want to advance your career, keep looking for mentors. Don't expect to find one after a short search either. I've been seeking my next mentor for years.
At the same time, there is a point in time that you will have to fly on your own. Losing a mentor is not a sad event (usually). Every mentor/mentee relationship I've ever had ends in the same state, in a strong relationship between friends and equals, where both are better off than they started. In at least one case, the person I was a mentor to quickly surpassed me in my chosen career, and that was one of the prouder moments of my life.
Be Patient and Insistent
Patience by itself is a virtue, but doesn't gain what you need. You must be not just persistent, but insistent to get what you want. The persistent person will try the same thing over, saying this must be the way out. An insistent person will try different approaches, saying, there must be a way out. Keep your goal in mind and be patient and insistent in achieving the goal, rather than any specific solution, and you will find what you are looking for.
This is probably not the answer you were looking for when you asked me that question. If you want a simple formula, I simply don't have one. I meandered through mine fields to get here. It was through incredible luck, incredible mentors, and incredible patience andperinsistence that I've reached the middle of the mine field, and I plan on someday getting through to the other side.
Be Passionate
Few people I know in the standards space ever planned to be where they are now. That goes for me in spades. If you had told me in my misspent youth that I'd be reading House, Senate and Conference editions of healthcare bills in the same week, or that I'd be commenting on federal regulation and be taken seriously, or that the work I'd been doing would impact as many lives as I think it does now, I'd have laughed you right out of the room. I never planned to be in this career, but once I found it, and acknowledged it as a calling, I latched onto it hard and with great passion.
That's my first tip. Be passionate about what you are doing. Being passionate is not just about loving your work, or having fun at your job, it's about taking it really seriously, and loving it at the same time, even when it sucks. If you don't love doing this work, you won't succeed in it. There will be times that what you have to do to get a job finished sucks: It may be tedious and boring, impossibly frustrating or just plain painfully unrewarding. You have to learn to take your rewards from a job successfully done, and done well, and with the impact that it can have on people. Financially, the job can be rewarding, but if financial reward is your measure of success, this job isn't for you.
Become an Expert
What do I need to learn? You need to learn something at the expert level. That requires a good deal of commitment. It's not just about spending 10,000 hours on something, but being passionate while you do it. And by something, I mean something that others will value enough to seek you out for your expertise. I can't tell you what to learn. I can tell you to pick something where people are already confused and seeking help. It's helpful to have another expert to rely on to help you out, but that isn't necessary. It's a lot easier to become first in a field of one than it is to become first in a field of 10. And if there are already 10 experts in your chosen field, branch out a bit. What good is one more expert when there are already 10?
To learn something at the expert level means that you have to understand how the parts it relies upon work together. You have to be more than a novice at XML before you will ever become an expert in CDA. If you don't understand how XML and XML Schema work, there will be things about CDA that you just won't understand. If you don't understand how a combustion engine works, you'll never become expert on motorcycles. That doesn't mean, by the way, that you need to have expert skills in the underlying components, but it might. The closer ties that the two things have, the more you need to know.
Have other Experiences
Being an expert about X is useless if you cannot apply X to problem Y. You need to learn enough about problem Y as it relates to X. I have skills in database management, natural language processing, data compression, digital signal processing, text processing, text and graphics rendering, text markup, and document analysis. Those skills were developed over a twenty year career before I ever got into CDA and Healthcare.
Some of the best CDA experts in the world got their start in SGML. At least one CDA consulting firm I know is made up of numerous people who had SGML, or similarly related skills first. CDA experience (and subsequent expertise) came with the job.
Learn something new as part of your routine. Challenge yourself. Read a book that you don't understand fully. Skip the parts you don't understand and then go back and read them again later. One of the coolest things that I love about my job is when two (or more) things I've read go click, and all of the sudden, I gain a new insight.
Develop a Network
When I work on a problem, you don't get just me. You get Glen and Charles and John and Harry and Lori and Gila and Bob and Tom and Rob and Tim and ... the rest of my network. You aren't alone, don't act that way. Call on your friends and colleagues to get their advice. Listen also to your critics as well. Then make your own judgement, and use what you found valuable. At the same time, when others call on you, offer your best efforts to help them out when you can.
The Health IT standards world may look like the good ole boy network, but it's not because the entry criteria is different. That's where being an expert is important, because experts often need other experts, and will work well with other experts they respect, even when they disagree. Some of the people I most respect in this field are ones I also have the most interesting arguments with.
Find (and Lose) a Mentor
I can count on one hand the number of mentors I've had in my life, and the number of people I've been a mentor too. It's a very special relationship, and incredibly valuable on both sides. If you want to advance your career, keep looking for mentors. Don't expect to find one after a short search either. I've been seeking my next mentor for years.
At the same time, there is a point in time that you will have to fly on your own. Losing a mentor is not a sad event (usually). Every mentor/mentee relationship I've ever had ends in the same state, in a strong relationship between friends and equals, where both are better off than they started. In at least one case, the person I was a mentor to quickly surpassed me in my chosen career, and that was one of the prouder moments of my life.
Be Patient and Insistent
Patience by itself is a virtue, but doesn't gain what you need. You must be not just persistent, but insistent to get what you want. The persistent person will try the same thing over, saying this must be the way out. An insistent person will try different approaches, saying, there must be a way out. Keep your goal in mind and be patient and insistent in achieving the goal, rather than any specific solution, and you will find what you are looking for.
This is probably not the answer you were looking for when you asked me that question. If you want a simple formula, I simply don't have one. I meandered through mine fields to get here. It was through incredible luck, incredible mentors, and incredible patience and
Sunday, April 7, 2013
أنا كيث بون
For those that cannot read Arabic, a semi-literal translation is I am Keith Boone. The Arabic script reads right to left, rather than left to right, and while there are no capital letters, each character in the script takes on a slightly different appearance depending on whether it appears at the beginning, middle or end of the word.
Arabic script is an Abdjad, essentially a syllabary but missing vowels (because those sounds are inferred by rules of the language). Japanese writing uses a syllabary that has consonant sounds built in and from that we have the ひらがな and カタカナ writing systems as well as romanji transcriptions commonly used for those names (Hiragana and Katakana respectively).
In healthcare, one of the challenges with matching names is that the best matching algorithm varies depending upon the cultural patterns associated with the name. And so, in a culture where the name patterns are Arabic, the name matching algorithm needs to account for that as a source of possible variation. One of the popular names in the world is that of مُحَمَّد, also the name of the prophet of Islam. There's really only one way to spell it Arabic, but at least 9 different spelling variations using the Roman alphabet.
In countries where Arabic is the official language it is still challenging because most software still doesn't deal well with the Arabic writing system, especially given the script changes necessary for rendering an the beginning, middle and end of the word. It wasn't until the advent of smart fonts in the late-1990's/early-2000's that software could really deal with the script changes necessary to properly render Arabic script on many computers, and those capabilities weren't well integrated into operating systems (some would argue that they still aren't) until a decade or more later. And so, Arabic names are still often romanized when entered into that software.
But knowing that the name was a romanized form of an Arabic name is a crucial hint that name matching software can use to better determine how to look up appropriate matches.
One might be tempted to offer this hint to the name matching software, for example using the IHE PDQ Version 3 Query's matching algorithm parameter. In fact, I even suggested this idea myself. But I'm probably very wrong to do so, as I think about it.
If I were designing a search algorithm to locate names in a master patient index, I'd probably leave the algorithm tuning to the computer. Here's how I would go about it:
In the context of looking a patient up by name and potentially other demographics, there are many other features present that may provide this and many other hints about how to tune the name matching algorithm. This includes location (e.g., Riyadh, where I am now), nationality, place of birth, et cetera, and these values may also be provided in the query.
These features, along with the character sequences in the name (and other fields), become a set of features which can be used to compare two names for a proximity match. In the fields of machine learning and linguistics, there are sufficient ways to describe features and feature distances, and to combine these into matching algorithms. It's a Big Data problem, and the computer will be better at determine which features will be helpful to decide on the matching algorithm. I'd let it do that work, and it would do a much better job than my simple hint.
What might be the most important that could be provided in a name matching algorithm is something that the receiving system doesn't necessarily know, and cannot deduce or induce from the data that it is provided. What information is that? It might well be the keyboard layout or input device used to enter the name. If the device is the tiny little keypad on my smartphone, the kinds of human input errors I make will be far different than if from my keyboard.
This is where human interface design intersects with something with what many would consider to be a largely compute bound, human interface free context. But it's not. There's spelling correction mistakes I make on my phone (or that my phone makes for me) that I would never make on a real keyboard.
Peace.
-- Keith
Arabic script is an Abdjad, essentially a syllabary but missing vowels (because those sounds are inferred by rules of the language). Japanese writing uses a syllabary that has consonant sounds built in and from that we have the ひらがな and カタカナ writing systems as well as romanji transcriptions commonly used for those names (Hiragana and Katakana respectively).
In healthcare, one of the challenges with matching names is that the best matching algorithm varies depending upon the cultural patterns associated with the name. And so, in a culture where the name patterns are Arabic, the name matching algorithm needs to account for that as a source of possible variation. One of the popular names in the world is that of مُحَمَّد, also the name of the prophet of Islam. There's really only one way to spell it Arabic, but at least 9 different spelling variations using the Roman alphabet.
In countries where Arabic is the official language it is still challenging because most software still doesn't deal well with the Arabic writing system, especially given the script changes necessary for rendering an the beginning, middle and end of the word. It wasn't until the advent of smart fonts in the late-1990's/early-2000's that software could really deal with the script changes necessary to properly render Arabic script on many computers, and those capabilities weren't well integrated into operating systems (some would argue that they still aren't) until a decade or more later. And so, Arabic names are still often romanized when entered into that software.
But knowing that the name was a romanized form of an Arabic name is a crucial hint that name matching software can use to better determine how to look up appropriate matches.
One might be tempted to offer this hint to the name matching software, for example using the IHE PDQ Version 3 Query's matching algorithm parameter. In fact, I even suggested this idea myself. But I'm probably very wrong to do so, as I think about it.
If I were designing a search algorithm to locate names in a master patient index, I'd probably leave the algorithm tuning to the computer. Here's how I would go about it:
In the context of looking a patient up by name and potentially other demographics, there are many other features present that may provide this and many other hints about how to tune the name matching algorithm. This includes location (e.g., Riyadh, where I am now), nationality, place of birth, et cetera, and these values may also be provided in the query.
These features, along with the character sequences in the name (and other fields), become a set of features which can be used to compare two names for a proximity match. In the fields of machine learning and linguistics, there are sufficient ways to describe features and feature distances, and to combine these into matching algorithms. It's a Big Data problem, and the computer will be better at determine which features will be helpful to decide on the matching algorithm. I'd let it do that work, and it would do a much better job than my simple hint.
What might be the most important that could be provided in a name matching algorithm is something that the receiving system doesn't necessarily know, and cannot deduce or induce from the data that it is provided. What information is that? It might well be the keyboard layout or input device used to enter the name. If the device is the tiny little keypad on my smartphone, the kinds of human input errors I make will be far different than if from my keyboard.
This is where human interface design intersects with something with what many would consider to be a largely compute bound, human interface free context. But it's not. There's spelling correction mistakes I make on my phone (or that my phone makes for me) that I would never make on a real keyboard.
Peace.
-- Keith
Friday, April 5, 2013
Implementation is always the real test
When HL7 implemented the board decision at the beginning of the week to make selected IP free, many of you noted that DSTUs were still marked as being available to members only. The board intention somehow was not implemented as some (including me) thought it had been clearly specified. I'm told that will be corrected shortly now that the board has clarified its intentions.
I certainly never expected DSTUs (including CCDA) to be treated any different from anything else.
It just goes to show you that what seems to be obvious isn't always.
I don't think even RFC 6919 would have helped here.
I certainly never expected DSTUs (including CCDA) to be treated any different from anything else.
It just goes to show you that what seems to be obvious isn't always.
I don't think even RFC 6919 would have helped here.
Thursday, April 4, 2013
It means what I want it to
We struggled for the longest time today trying to figure out how to say the following in HQMF:
Find me the first instance of this medication (e.g., Aspirin), in these kinds of encounters (e.g., ED visits where DX = MI).
The challenge wasn't the medication, or the type of encounter, or even encounters where DX = MI, but rather how to apply FIRST and DURING operations at the same time so that FIRST returned more than one item. E.g., it was the first item of its type in the time period expressed by the temporal relationship.
We struggled with it for quite a while, and I'd written something on the board, and then Dragon pointed out that we'd added the <subsetCode> attribute to the <temporallyRelated> act relationship and it all came together.
I don't know what that means I said, but we can define it to mean what we want it to. Marc said "Wait, let me see if I can make this work before I agree." and he started digging into code. The rest of use looked at it some more to poke more holes in it. "Does it still work if we change LAST to FIRST?" I asked, and yes it did. "Does it work if we use a different temporal relationship?" I asked again, "Like BEFORE?" Chimed in Dragon. Yep, that worked too. And Marc said, "Yes, I can make it work. I like this."
And so, even though we weren't sure what it meant when we looked at it at first, by the time we were done, it meant exactly what we wanted it to, and it wasn't even a stretch to believe that someone had actually designed it to work that way.
So now, if you want to know what the average time is for a patient who needs it to be given Aspirin in the ED if they are having a heart attack, we know how to A) specify that measure, and B) compute it from the specification. Being able to do A is nice, but the biggest change in HQMF Release 2 is that we can do so much more of B from A.
Keith
Find me the first instance of this medication (e.g., Aspirin), in these kinds of encounters (e.g., ED visits where DX = MI).
The challenge wasn't the medication, or the type of encounter, or even encounters where DX = MI, but rather how to apply FIRST and DURING operations at the same time so that FIRST returned more than one item. E.g., it was the first item of its type in the time period expressed by the temporal relationship.
We struggled with it for quite a while, and I'd written something on the board, and then Dragon pointed out that we'd added the <subsetCode> attribute to the <temporallyRelated> act relationship and it all came together.
I don't know what that means I said, but we can define it to mean what we want it to. Marc said "Wait, let me see if I can make this work before I agree." and he started digging into code. The rest of use looked at it some more to poke more holes in it. "Does it still work if we change LAST to FIRST?" I asked, and yes it did. "Does it work if we use a different temporal relationship?" I asked again, "Like BEFORE?" Chimed in Dragon. Yep, that worked too. And Marc said, "Yes, I can make it work. I like this."
And so, even though we weren't sure what it meant when we looked at it at first, by the time we were done, it meant exactly what we wanted it to, and it wasn't even a stretch to believe that someone had actually designed it to work that way.
So now, if you want to know what the average time is for a patient who needs it to be given Aspirin in the ED if they are having a heart attack, we know how to A) specify that measure, and B) compute it from the specification. Being able to do A is nice, but the biggest change in HQMF Release 2 is that we can do so much more of B from A.
Keith
Wednesday, April 3, 2013
Back to QueryHealth and HQMF and a gratuitous Star Trek reference

We are trying to finish up HQMF Release 2.0 this week, seven of us, meeting in MITRE's offices in Bedford, MA. Initially this meeting was scheduled so that we could complete the big push to get the standard out in time to be referenced in Meaningful Use stage 3. With CMS' announcement that Stage 3 will not come out this year, I don't see the need to rush, rather I'd like to get it done well.
One of the challenges we worked out today was how to combine and reuse different criteria. We worked out a fairly elegant solution that allows a data criterion to be further refined, or be used with other criteria in union and/or intersection operations. We also worked out some simplifications around excerpts, realizing that we could just limit ourselves to FIRST, LAST, MIN and MAX and use that to be able to support Nth, or Nth from the end, without having to support the entire value set possible.
There are a few other simplifications in the works, and the combine and reuse solution also seems to allow us to address what I had quickly relabeled the 7 of 9 problem. The problem is that some measure developers want to be able to create numerator or denominator criteria where what is being counted meets N out of M other criteria. This is a pattern than is often used in certain kinds of assessment instruments, and rather than using an assessment result, you could just compute it based on the known data. Using the combination solution, there's a way we can say that.
Tuesday, April 2, 2013
Some Restrictions Apply
Yesterday, HL7 implemented a policy that I've been working towards as a member of the HL7 Board for quite some time. Under that policy, anyone can implement HL7 standards in their products without paying a license fee to HL7.
Yes, you can download the standards from the HL7 web site today without charge. They do ask you to do a couple of things (hence, the title of this post):
Yes, you can download the standards from the HL7 web site today without charge. They do ask you to do a couple of things (hence, the title of this post):
- Register on their website.
- Agree abide by the license terms and policy.
- Update your agreement status annually.
Is that so hard? What this means for developers is that you can use the HL7 standards free of charge to develop software products. It doesn't mean that you can incorporate parts of the standard into your documentation, or give parts of it to your customers, or otherwise distribute it.
Organizational members still retain some of those benefits that non-members aren't freely given. They are able to share copies of the standard internally to their organization and to share parts of it (not whole chapters or domains) with their customers, or use parts of it to create implementation guides or product documentation.
Some will complain that it's not fair that members can still do things with the standards than non-members cannot. I have to say that if it has value, then maybe you should be willing to pay something for it.
Over time, I think the "paper work" to download the standard (which takes all of about 15 seconds to fill out) will get even less intimidating. For now, we probably need to give the lawyers their due.
Personally, I think that the new policy is a great move in the right direction. What do you think? Have you downloaded the standards yet?
Keith
Monday, April 1, 2013
I don't know is not the same as none
I keep hearing that "There's no standards for that.", or that "There's too many optional features in that data element." Sometimes these pronouncement come from people who should know better (at least by reputation, not necessarily according to knowledge or skill), and other times, it simply comes from folks who don't know that there are other places to look.
I think the main challenge is that so many folk looking for standards don't know what is there or where to look. Organizations like HL7, IHE, IHTSDO, and LOINC that put forth such standards don't necessarily make them easily accessible in ways that implementers expect.
Clinicians and researchers are accustomed to looking up stuff in publication directories such as MedLine/PubMed. Developers are accustomed to looking to publications from one or two (or maybe even three) SDOs or profiling organizations.
We can readily determine at a clinical level the appropriate treatment for a particular disease, or how to effectively use a particular medication, but have no similar resource to determine appropriate ways to communicate information about a particular disease or treatment to those who need to automate it.
USHIK is a good start for those of us working the US, but it doesn't really address the issue. For example, what do you need to know about communicating an A1C result?
I think the main challenge is that so many folk looking for standards don't know what is there or where to look. Organizations like HL7, IHE, IHTSDO, and LOINC that put forth such standards don't necessarily make them easily accessible in ways that implementers expect.
Clinicians and researchers are accustomed to looking up stuff in publication directories such as MedLine/PubMed. Developers are accustomed to looking to publications from one or two (or maybe even three) SDOs or profiling organizations.
We can readily determine at a clinical level the appropriate treatment for a particular disease, or how to effectively use a particular medication, but have no similar resource to determine appropriate ways to communicate information about a particular disease or treatment to those who need to automate it.
USHIK is a good start for those of us working the US, but it doesn't really address the issue. For example, what do you need to know about communicating an A1C result?
- What standard is used to order this test?
- What standard is used to communicate the results of this test?
- What standards are used to transport the information in steps 1 and 2?
- What code is or should be used to identify the result in step 2?
- How do we codify units?
- What other data need to be communicated to the lab to perform this test?
- How do we communicate the normal range for results?
- What information in the above is necessary to make determinations about quality of care related to this test?
- Among all variations in 1-7, how do we identify the right combinations that should be used for quality measurement?
I could answer the questions above, but I can tell you that there are likely to be eight or nine different publications that the implementers need to be aware of. And none of these really address any of the clinical issues, just the technical issues with respect to the communication.
Subscribe to:
Comments (Atom)